
Balancing Accuracy and Efficiency in Language Models
Introduction
Recent advancements in large language models (LLMs) have significantly improved their reasoning abilities, particularly through reinforcement learning (RL) based fine-tuning. This two-phase RL post-training approach enhances both accuracy and efficiency while addressing common misconceptions about response length and reasoning quality.
Understanding the Two-Phase RL Approach
Phase One: Enhancing Reasoning Ability
The initial phase focuses on improving the model’s reasoning skills using supervised learning for token prediction, followed by RL post-training. This phase encourages models to explore various reasoning paths, leading to self-correction and improved accuracy.
Phase Two: Promoting Conciseness
The second phase utilizes a targeted dataset to enforce conciseness. By encouraging shorter responses that still maintain accuracy, this phase reduces computational costs and response times. Recent studies have shown that shorter, precise answers are often more accurate than longer, verbose ones.
Practical Business Solutions
1. Implementing Efficient Models
Businesses can benefit from using smaller, faster models that require less computational power while still delivering competitive performance. For instance, the Kimi model has shown strong results against larger models like GPT-4 while using fewer tokens.
2. Utilizing Prompt Engineering
Applying strategic prompt engineering can help reduce verbosity in responses. This not only enhances user experience but also minimizes processing time and costs.
3. Training on Diverse Problem Sets
Training models on problems of varying difficulty can enhance their ability to generate concise, accurate responses. For example, a two-phase RL strategy has demonstrated notable performance gains across different model sizes, especially when easier problems are introduced.
4. Monitoring Key Performance Indicators (KPIs)
It’s crucial to identify and track KPIs to assess the impact of AI investments on business performance. This ensures that the implemented solutions are achieving the desired outcomes.
5. Starting Small and Scaling Up
Businesses should begin with small AI projects, gather data on effectiveness, and gradually expand their use of AI. This iterative approach allows for adjustments based on real-world feedback.
Case Studies and Insights
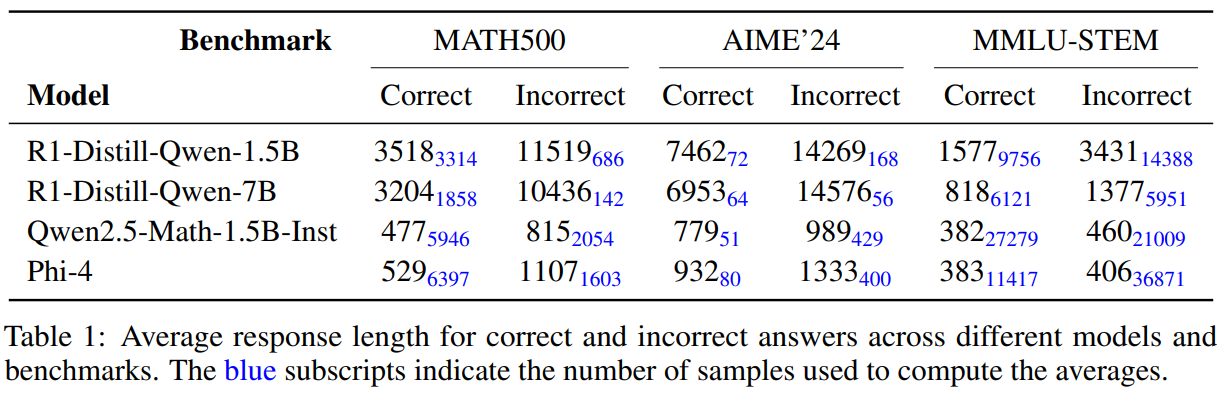
Research conducted by Wand AI reveals that longer responses do not necessarily equate to better reasoning. Their findings show that concise answers correlate with higher accuracy and that excessive verbosity can lead to decreased performance. In fact, models trained with minimal RL refinement have demonstrated significant accuracy improvements—up to 30%—even with limited problem sets.
Conclusion
The two-phase RL post-training method presents an effective solution for enhancing reasoning and conciseness in language models. By focusing on both accuracy and brevity, businesses can optimize their AI applications for improved efficiency. The evidence suggests that shorter responses can be equally, if not more, effective than longer ones, challenging traditional assumptions about reasoning quality.
In summary, adopting this approach not only streamlines processes but also maximizes the impact of AI investments. For businesses looking to harness the power of AI, understanding and implementing these strategies is key to achieving optimal results.
If you require further assistance in managing AI within your business, please reach out to us at hello@itinai.ru. You can also connect with us on Telegram, X, and LinkedIn.




















