
NVIDIA’s UltraLong-8B: Transforming Language Models for Business Applications
Introduction to UltraLong-8B
NVIDIA has recently launched the UltraLong-8B series, a new set of ultra-long context language models capable of processing extensive sequences of text, reaching up to 4 million tokens. This advancement addresses a significant challenge faced by large language models (LLMs), which often struggle with lengthy documents or videos due to their limited context windows. As a result, critical information can be overlooked, hindering effective document and video understanding, in-context learning, and inference-time scaling.
Challenges with Current Language Models
Current LLMs, such as GPT-4o and Claude, have made strides in handling longer contexts but often remain closed-source, limiting reproducibility. Open-source alternatives like ProLong and Gradient have emerged, yet they often involve high computational costs or do not fully address the performance trade-offs between long and short context tasks.
Innovative Solutions for Long Contexts
Efficient Training Strategies
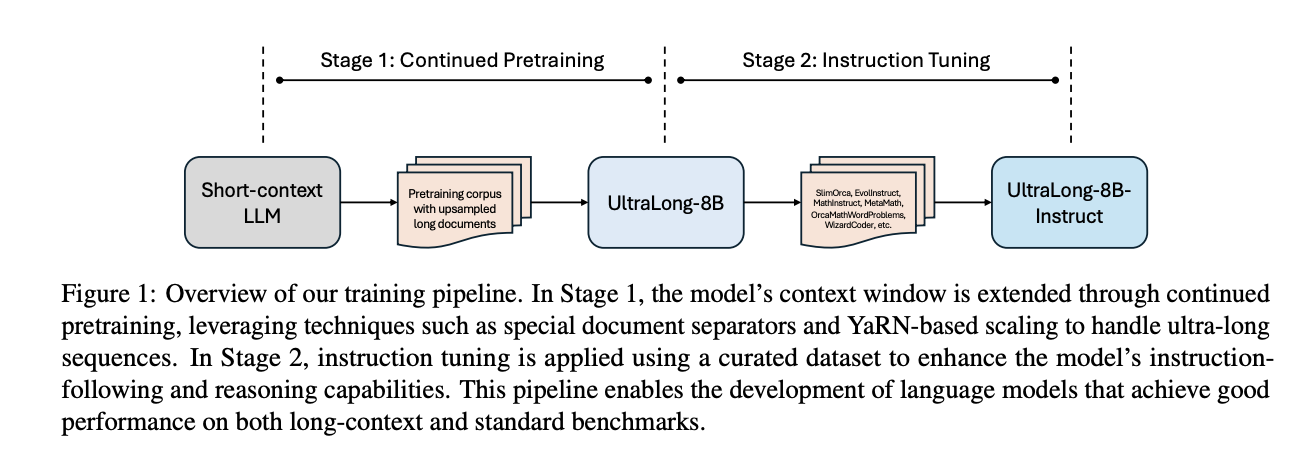
Researchers from the University of Illinois Urbana-Champaign and NVIDIA have proposed a systematic training approach that extends context lengths from 128,000 tokens to 1 million, 2 million, and even 4 million tokens. This method employs:
- Continued Pretraining: Enhances the model’s ability to process ultra-long inputs.
- Instruction Tuning: Maintains high performance on standard tasks while improving reasoning and instruction-following capabilities.
Performance Metrics
The UltraLong-8B model has demonstrated exceptional performance across various benchmarks, achieving:
- 100% accuracy in long-context retrieval tests.
- Top average scores on RULER for inputs up to 1 million tokens.
- Best performance on InfiniteBench and high F1 scores on LV-Eval for token lengths of 128K and 256K.
Case Studies and Statistics
For instance, in the Needle in a Haystack retrieval test, baseline models struggled, while UltraLong models consistently performed at peak accuracy across all input lengths. This capability is crucial for businesses that rely on extensive data analysis and retrieval from large datasets.
Future Directions
While the current approach focuses on supervised fine-tuning (SFT) with instruction datasets, future research aims to integrate safety alignment mechanisms and explore advanced tuning strategies. This will enhance the models’ performance and trustworthiness in business applications.
Practical Business Solutions
To leverage AI effectively in your organization, consider the following steps:
- Identify Automation Opportunities: Look for processes that can be streamlined or automated using AI.
- Focus on Key Performance Indicators (KPIs): Establish metrics to evaluate the impact of your AI investments on business outcomes.
- Select Customizable Tools: Choose AI tools that can be tailored to meet your specific business needs.
- Start Small: Initiate a pilot project, gather data on its effectiveness, and gradually scale up your AI utilization.
Conclusion
The introduction of NVIDIA’s UltraLong-8B series marks a significant advancement in language model capabilities, particularly for processing long sequences of text. By adopting efficient training strategies and focusing on practical applications, businesses can harness the power of AI to enhance their operations and decision-making processes. As the field evolves, staying informed and adaptable will be key to maximizing the benefits of these technologies.























