
Enhancing Reasoning in Language Models Through Inference-Time Scaling
Introduction
Large language models have gained acclaim for their fluency in language, yet improving their reasoning capabilities is increasingly vital—particularly for complex problem-solving scenarios. These challenges encompass tasks requiring advanced mathematical reasoning, spatial logic, pathfinding, and structured planning. For success in these areas, models must exhibit a human-like ability to navigate through multi-step problems where immediate solutions are not readily available. Consequently, the behavior of these models during inference time has emerged as an essential area of study.
The Challenges of Current Models
Despite advancements in model design and training methods, many language models struggle with multi-step or challenging reasoning tasks. A significant issue is that while these models have access to a wealth of information, they often lack the strategies needed to utilize this information effectively across various steps. For instance, tasks involving scheduling with constraints or solving NP-hard problems require continuous logical reasoning, which standard models frequently find challenging. Methods such as simply increasing model parameters or storage space may show limited effectiveness as task complexity rises.
Innovative Solutions to Improve Reasoning
In response to these limitations, researchers are exploring advanced techniques such as:
- Chain-of-thought prompting: Guiding models through reasoning processes step-by-step.
- Post-training fine-tuning: Adjusting models after initial training to better match complex task requirements.
- Multiple answer generation: Creating several independent answers and selecting the most plausible one using heuristics.
- Self-refinement: Encouraging the model to critique and improve its own answers.
These methods have shown varying levels of success across established models like GPT-4o and Claude 3.5 Sonnet, highlighting the need for improved consistency and accuracy across benchmarks.
Microsoft’s Evaluation Framework
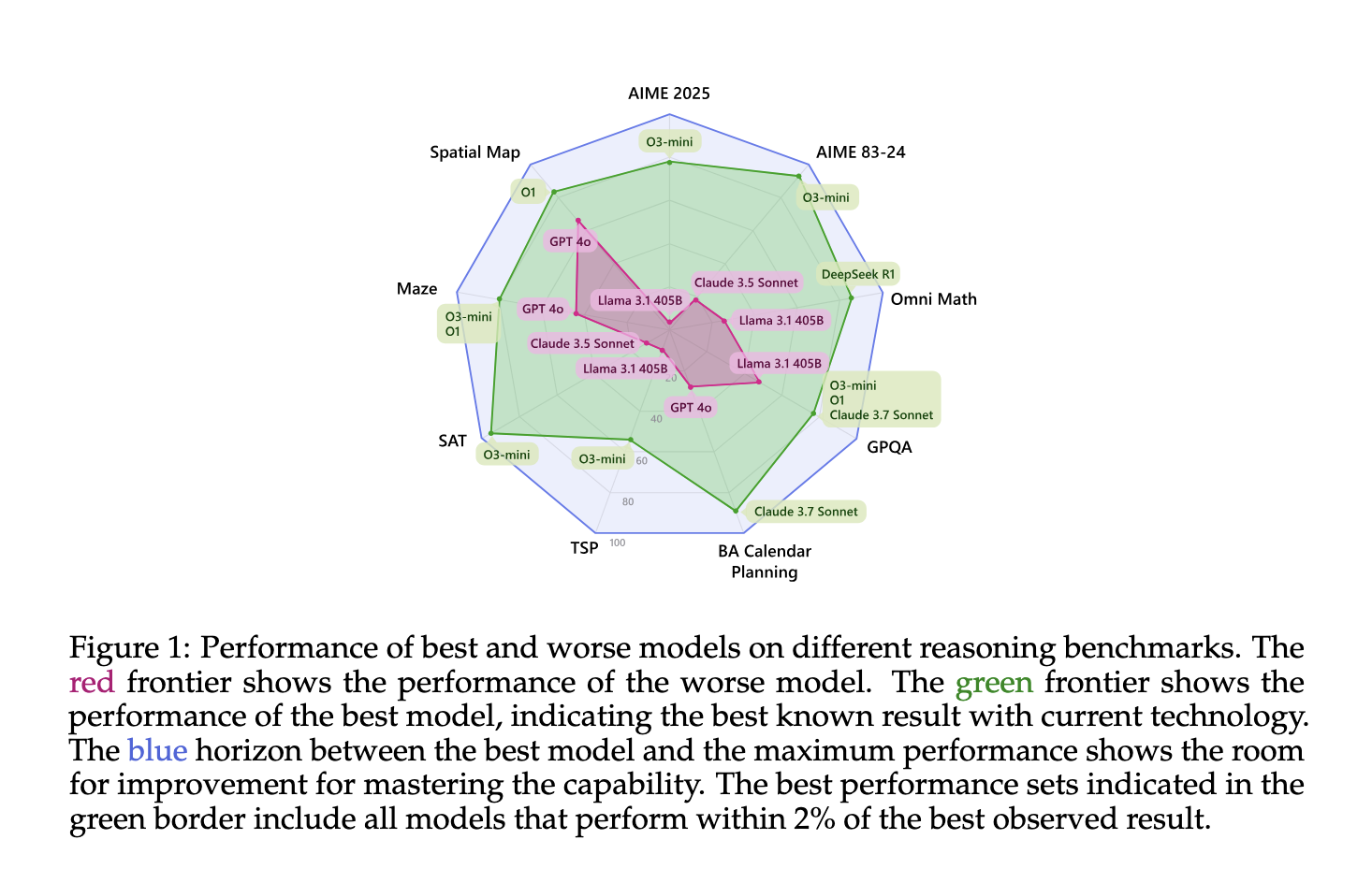
Microsoft introduced a comprehensive evaluation framework focused on inference-time scaling, examining nine different models against eight complex task benchmarks. This included a comparison between traditional models and those optimized for reasoning, such as DeepSeek R1, O1, and O3-mini. Their methodology utilized both parallel scaling—where multiple outputs are generated and aggregated—and sequential scaling—where iterative feedback refines outputs. Key benchmarks were drawn from various domains, including calendar planning and math Olympiads, alongside newly created datasets for NP-hard problems like 3SAT and TSP.
Core Strategies for Improvement
The research employed two primary strategies:
- Sampling multiple generations: Assessing result variability by generating several outputs.
- Critics for feedback: Using evaluators to simulate enhanced reasoning through iterative feedback.
In parallel scaling, models produce several potential answers, which are then evaluated using voting mechanisms. In sequential scaling, each output receives feedback, prompting the model to attempt revisions. This dual approach provided valuable insights into model performance and identified areas for potential improvement through enhanced computational scaling.
Performance Analysis and Findings
The analysis revealed notable differences in performance across models and tasks. For example:
- On the GPQA benchmark, model O1 achieved an accuracy of 90.9%, whereas GPT-4o reached 77.7%.
- In the TSP dataset, O1 consistently maintained over 80% accuracy, while GPT-4o’s peak performance only occurred with more than 20 inference calls.
- In calendar tasks, DeepSeek R1 outperformed competitors with an 88.5% accuracy rate.
The results emphasized that increasing token consumption does not necessarily correlate with higher accuracy. For instance, DeepSeek R1 used significantly more tokens than Claude 3.7 Sonnet yet offered only slight advantages in certain tasks.
Conclusion
This study highlights the shortcomings of traditional language models in complex reasoning tasks and underscores the importance of intelligent scaling—not merely increasing token usage. Feedback loops and robust evaluation criteria can lead to substantial improvements in accuracy, pointing to a promising future for reasoning models. Continued innovation in structured inference strategies and cost-effective token management remains essential for further advancements in this field.
Actionable Insights for Businesses
Explore how artificial intelligence can transform your operations:
- Identify processes ripe for automation—leverage AI to enhance interactions with customers and streamline workflows.
- Monitor key performance indicators (KPIs) to measure the impact of your AI investments accurately.
- Select tools that align with your unique needs and allow for customization to achieve your objectives.
- Initiate small-scale AI projects, analyze their effectiveness, and scale your AI applications gradually.
For additional guidance on managing AI in business contexts, please reach out to us at hello@itinai.ru or connect through our platforms on Telegram, X, and LinkedIn.


























