
Enhancing Vision-Language Understanding with New Solutions
Challenges in Current Systems
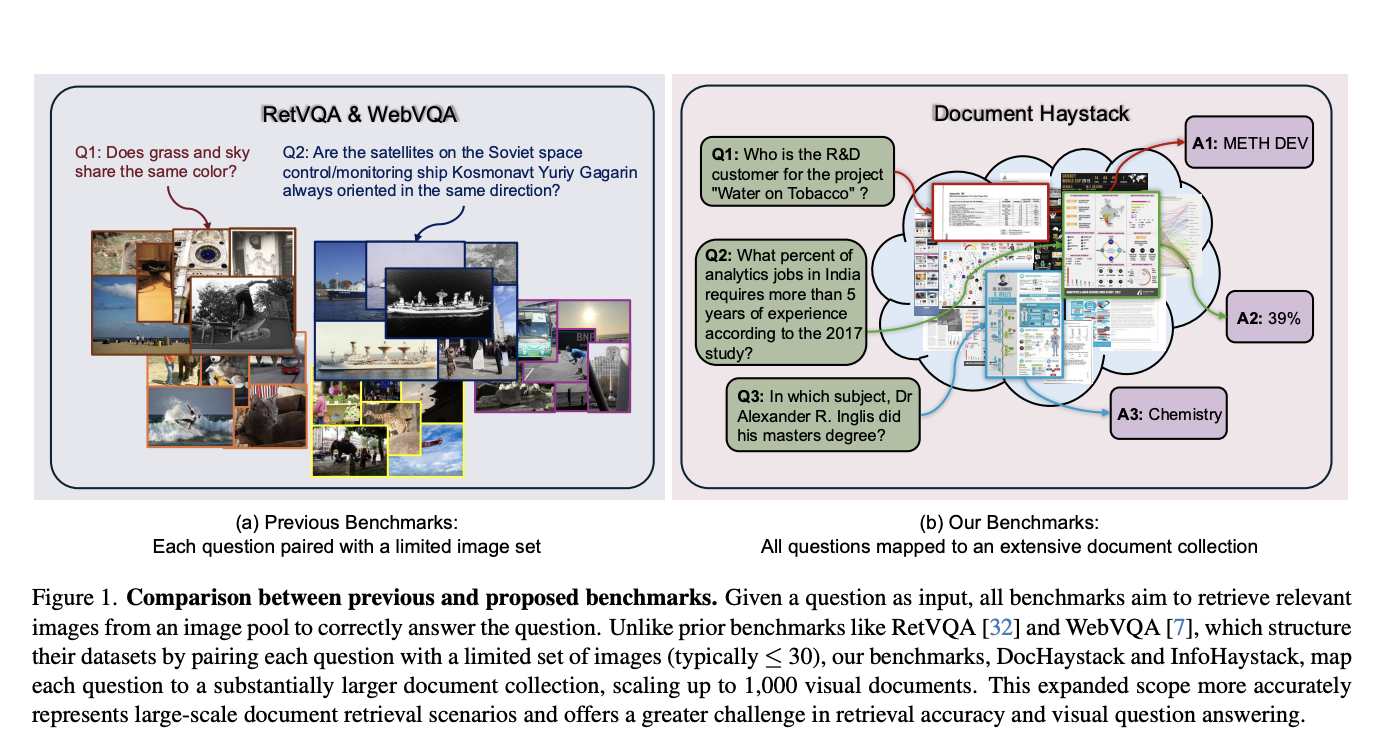
Large Multimodal Models (LMMs) have improved in understanding images and text, but they struggle with reasoning over large image collections. This limits their use in real-world applications like visual search and managing extensive photo libraries. Current benchmarks only test models with up to 30 images per question, which is inadequate for complex retrieval tasks.
New Benchmarks and Frameworks
To address these challenges, new benchmarks, DocHaystack and InfoHaystack, have been introduced. These require models to handle up to 1,000 documents, significantly broadening the scope of visual question-answering and retrieval tasks.
Retrieval-Augmented Generation (RAG)
The RAG framework improves LMMs by combining retrieval systems with generative models, making it easier to manage large image-text datasets. Innovative models like MuRAG, RetVQA, and MIRAGE enhance this process using advanced retrieval techniques.
Introducing V-RAG
The new V-RAG framework utilizes multiple vision encoders and a relevance module, leading to better performance on the DocHaystack and InfoHaystack benchmarks. It sets a higher standard for visual retrieval and reasoning tasks.
Research Contributions
Researchers from KAUST, the University of Sydney, and IHPC, A*STAR, developed the DocHaystack and InfoHaystack benchmarks to evaluate LMMs on large-scale tasks. These benchmarks simulate real-world situations by requiring models to process many documents, thus improving retrieval and reasoning capabilities.
Refining Document Retrieval
DocHaystack and InfoHaystack ensure that each question results in a unique answer by using a three-step curation process. This includes filtering questions, manual reviews, and eliminating general knowledge queries. The V-RAG framework enhances retrieval from large datasets through a combination of vision encoders and a filtering module for relevant documents.
Experiment Insights
The experiments section details the training setup and results for the V-RAG framework. Metrics such as Recall@1, @3, and @5 show that V-RAG outperforms existing models, achieving better recall and accuracy scores. Fine-tuning with curated distractor images further boosts performance.
Conclusion
This study introduces DocHaystack and InfoHaystack as benchmarks for assessing LMMs in large-scale retrieval tasks. The V-RAG framework integrates various vision encoders and a filtering module, leading to improved precision and reasoning capabilities. V-RAG achieves up to 11% higher Recall@1 scores, enhancing LMM performance in handling thousands of images.
Get Involved
Check out the research paper for more details. Stay updated by following us on Twitter, joining our Telegram Channel, and LinkedIn Group. If you appreciate our work, consider subscribing to our newsletter and joining our 60k+ ML SubReddit community.
Transform Your Business with AI
To evolve your company with AI and stay competitive, consider the following steps:
- Identify Automation Opportunities: Find key customer interactions that can benefit from AI.
- Define KPIs: Ensure your AI initiatives have measurable impacts on business outcomes.
- Select an AI Solution: Choose tools that fit your needs and offer customization.
- Implement Gradually: Start with a pilot project, gather data, and expand AI use wisely.
For AI KPI management advice, connect with us at hello@itinai.com. For ongoing insights into leveraging AI, follow us on Telegram or Twitter @itinaicom.
Discover how AI can transform your sales processes and customer engagement at itinai.com.


























