
Understanding Large Language Models (LLMs)
Large language models (LLMs) are advanced tools that can do more than just generate text. They can reason, learn to use tools, and even generate code. This has led to interest in creating LLM-based language agents to automate scientific discovery. The goal is to develop systems that can manage the entire research process, from idea generation to experiments and writing papers.
Challenges Ahead
However, achieving this vision comes with challenges. These include the need for strong reasoning skills, effective tool use, and the ability to navigate complex scientific inquiries. The true potential of these agents is still being debated among researchers.
Introducing ScienceAgentBench
Researchers from various departments have created ScienceAgentBench, a benchmark to evaluate language agents in data-driven discovery. This framework is based on three main principles:
- Scientific Authenticity
- Rigorous Graded Evaluation
- Multi-Stage Quality Control
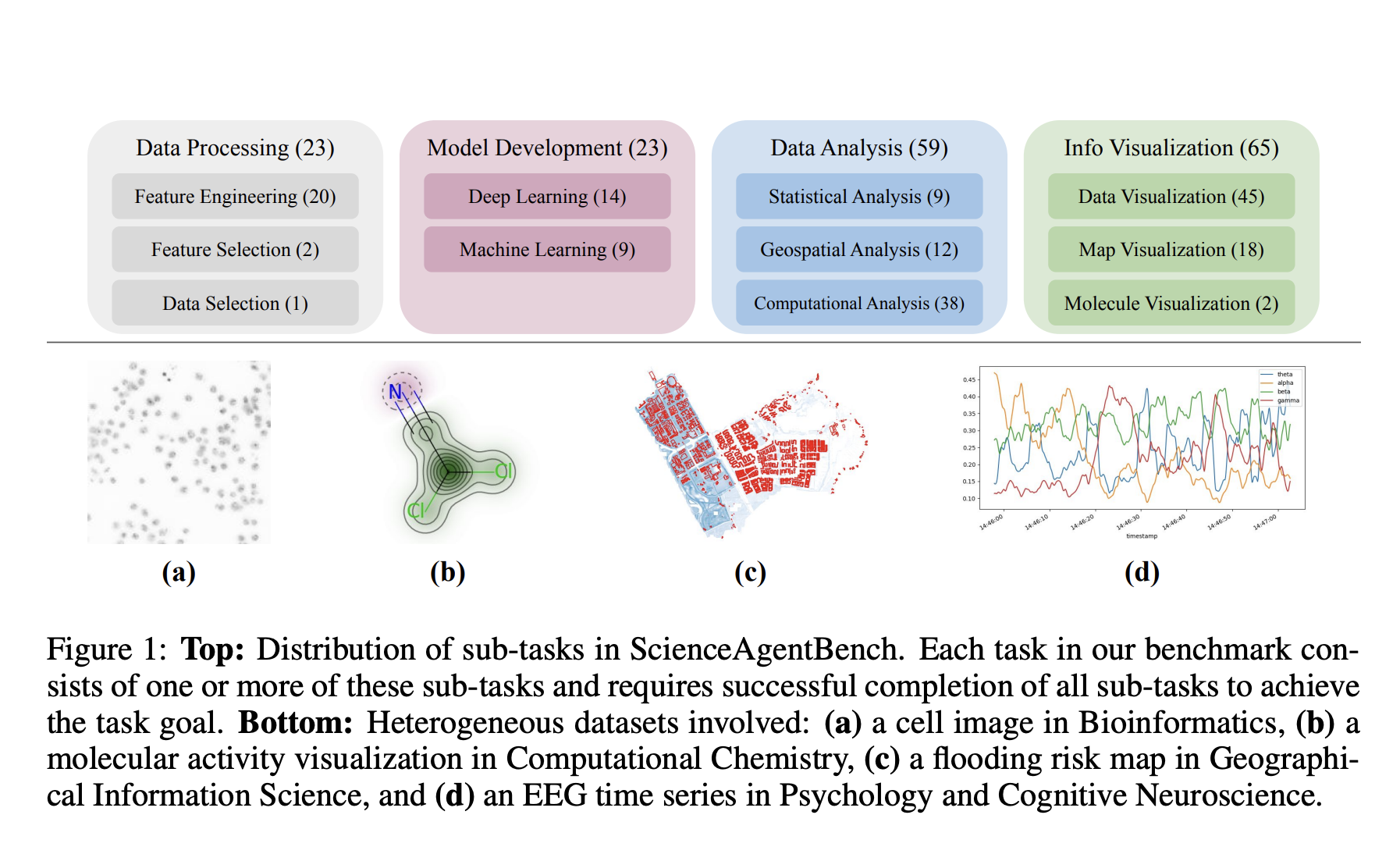
ScienceAgentBench includes 102 tasks from 44 peer-reviewed publications across four scientific fields, ensuring relevance and reducing generalization issues. It uses a consistent format of self-contained Python programs for evaluation, allowing for various metrics to assess generated code, execution results, and costs.
Task Components
Each task in ScienceAgentBench has four parts:
- Task Instruction: A clear description of the task.
- Dataset Information: Details about the data structure and content.
- Expert Knowledge: Context provided by experts in the field.
- Annotated Program: A program adapted from peer-reviewed work.
This careful construction process ensures that the evaluation is authentic and relevant.
Insights from Evaluations
Evaluations using ScienceAgentBench have provided valuable insights:
- The model Claude-3.5-Sonnet performed best, achieving a success rate of 32.4% without expert knowledge and 34.3% with it.
- This model significantly outperformed direct prompting methods.
- The self-debugging approach was particularly effective, nearly doubling success rates compared to simpler methods.
Despite these advancements, language agents still face challenges with complex tasks, especially in specialized fields like Bioinformatics and Computational Chemistry.
The Importance of ScienceAgentBench
ScienceAgentBench is crucial for evaluating language agents in scientific discovery. With only 34.3% of tasks solved by the best model, it highlights the limitations of current technology and the need for better evaluation methods. This benchmark is essential for developing improved language agents and enhancing scientific data processing.
Get Involved
Check out the research paper for more details. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. If you appreciate our work, subscribe to our newsletter and join our 50k+ ML SubReddit.
Upcoming Event
RetrieveX – The GenAI Data Retrieval Conference on Oct 17, 2023.
Transform Your Business with AI
To stay competitive, leverage ScienceAgentBench for your AI solutions:
- Identify Automation Opportunities: Find key areas for AI integration.
- Define KPIs: Ensure measurable impacts from your AI initiatives.
- Select an AI Solution: Choose tools that fit your needs.
- Implement Gradually: Start small, gather data, and expand wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights, follow us on Telegram or Twitter.
Discover how AI can enhance your sales processes and customer engagement at itinai.com.


























