
Understanding the Challenges of Large Language Models
The rapid growth of large language models (LLMs) has led to significant challenges in their deployment and communication. As these models become larger and more complex, they face issues with storage, memory, and network bandwidth. For example, models like Mistral transfer over 40 PB of data every month, highlighting the need for efficient data handling.
Storage and Bandwidth Issues
As models grow, their storage needs can increase dramatically, sometimes requiring hundreds of times the size of the original model for updates and checkpoints. This creates a burden on data transfer and storage systems.
Solutions for Model Compression
To address these challenges, researchers have developed various model compression techniques that aim to reduce model sizes while maintaining performance. The four main methods include:
- Pruning: Removes unnecessary parts of the model but may lose important information.
- Network Architecture Modification: Changes the structure of the model to make it more efficient.
- Knowledge Distillation: Trains a smaller model to mimic a larger one but might not capture all details.
- Quantization: Reduces the precision of calculations to save on storage and speed, but this can affect accuracy.
Introducing ZipNN
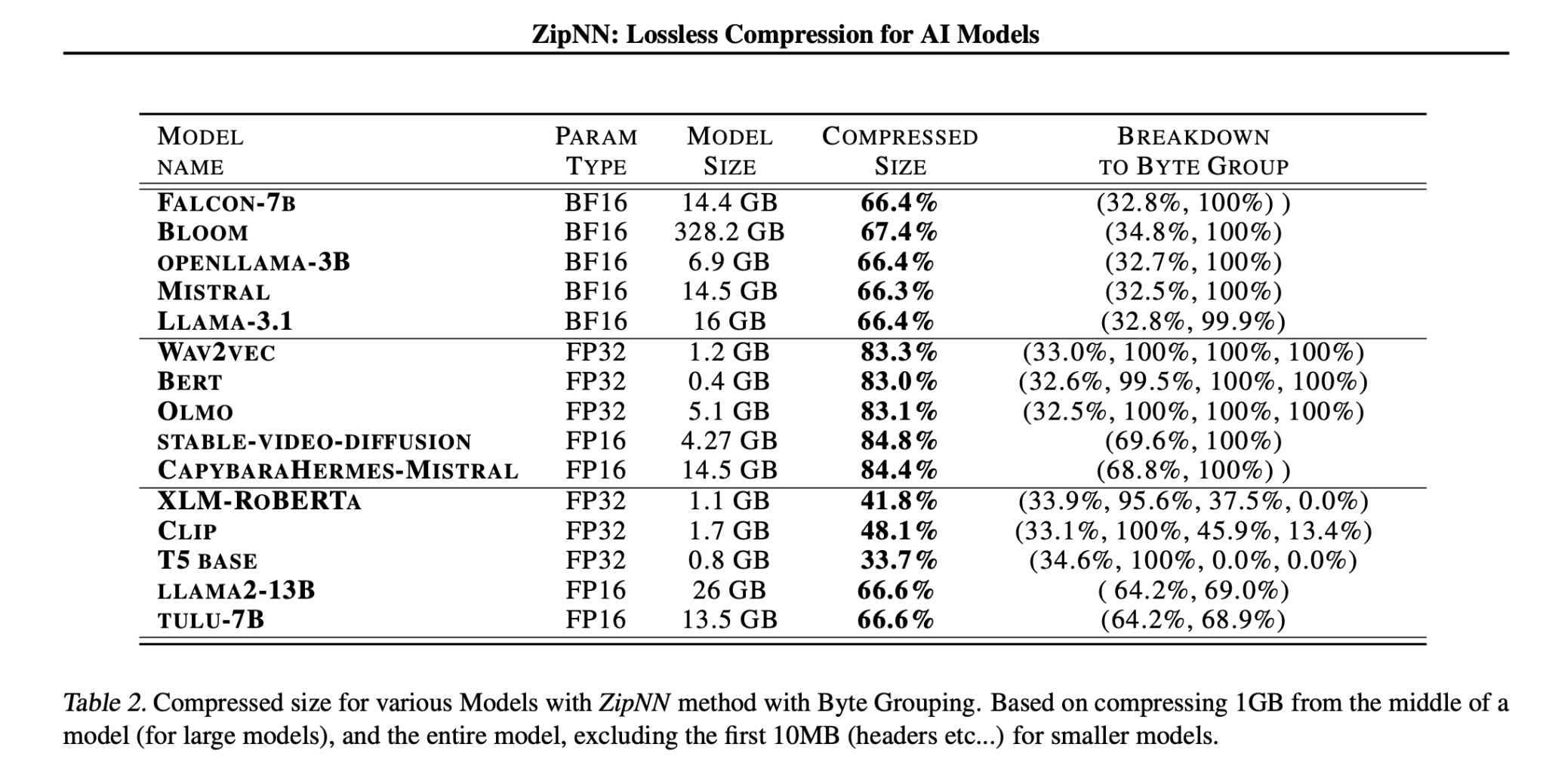
Researchers have introduced ZipNN, a lossless compression technique specifically designed for neural networks. This innovative method can reduce model sizes by up to 33%, and in some cases, even more than 50%. For example, ZipNN improves compression for models like Llama 3 by over 17% compared to traditional methods, while speeding up the compression and decompression process by 62%.
Benefits of ZipNN
ZipNN can significantly reduce network traffic, potentially saving an ExaByte of bandwidth each month for large model distribution platforms like Hugging Face.
Efficient Architecture
ZipNN is built for fast and parallel processing, primarily using C and Python. Its design allows it to process model segments independently, making it ideal for modern GPU systems. It features a two-level compression strategy and integrates seamlessly with the Hugging Face Transformers library for easy model management.
Performance Insights
Tests showed that while ZipNN may not be the fastest option, it offers substantial compression benefits. Cached downloads can be significantly faster than initial downloads, depending on the machine and network setup.
Key Takeaway
This research emphasizes that even as machine learning models grow, there are still many inefficiencies in their storage and communication. By applying targeted compression techniques like ZipNN, companies can save space and bandwidth without sacrificing model quality.
Get Involved
For further insights, check out the Paper and follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. If you’re interested in our work, consider subscribing to our newsletter and joining our 60k+ ML SubReddit.
Transform Your Business with AI
To leverage AI effectively in your company, consider using ZipNN:
- Identify Automation Opportunities: Find areas in customer interactions that can benefit from AI.
- Define KPIs: Ensure measurable outcomes from your AI initiatives.
- Select an AI Solution: Choose tools that fit your needs and offer customization.
- Implement Gradually: Start small, gather data, and expand your AI usage thoughtfully.
For advice on AI KPI management, contact us at hello@itinai.com. For ongoing insights, follow us on Telegram at t.me/itinainews or Twitter at @itinaicom.
Explore how AI can enhance your sales processes and customer engagement at itinai.com.


























