
Understanding Large Language Models (LLMs)
Large Language Models (LLMs) are advanced AI systems that rely on extensive data to predict text sequences. Building these models requires significant computational resources and well-organized data management. As the demand for efficient LLMs grows, researchers are finding ways to improve performance while minimizing resource use.
Challenges in Developing LLMs
Creating LLMs is challenging due to the need for high computational power and quality data. Models with billions of parameters require sophisticated techniques to ensure stability and performance during training. Open-source models often lag behind proprietary ones due to limited access to resources. The goal is to develop efficient models that allow smaller teams to contribute to AI advancements.
Innovative Training Techniques
Research focuses on improving data management through methods like data cleaning and dynamic scheduling. However, stability issues persist, especially during large-scale training. Techniques such as advanced optimizers and synthetic data generation are being explored to address these challenges, but more scalable solutions are needed.
Introducing YuLan-Mini
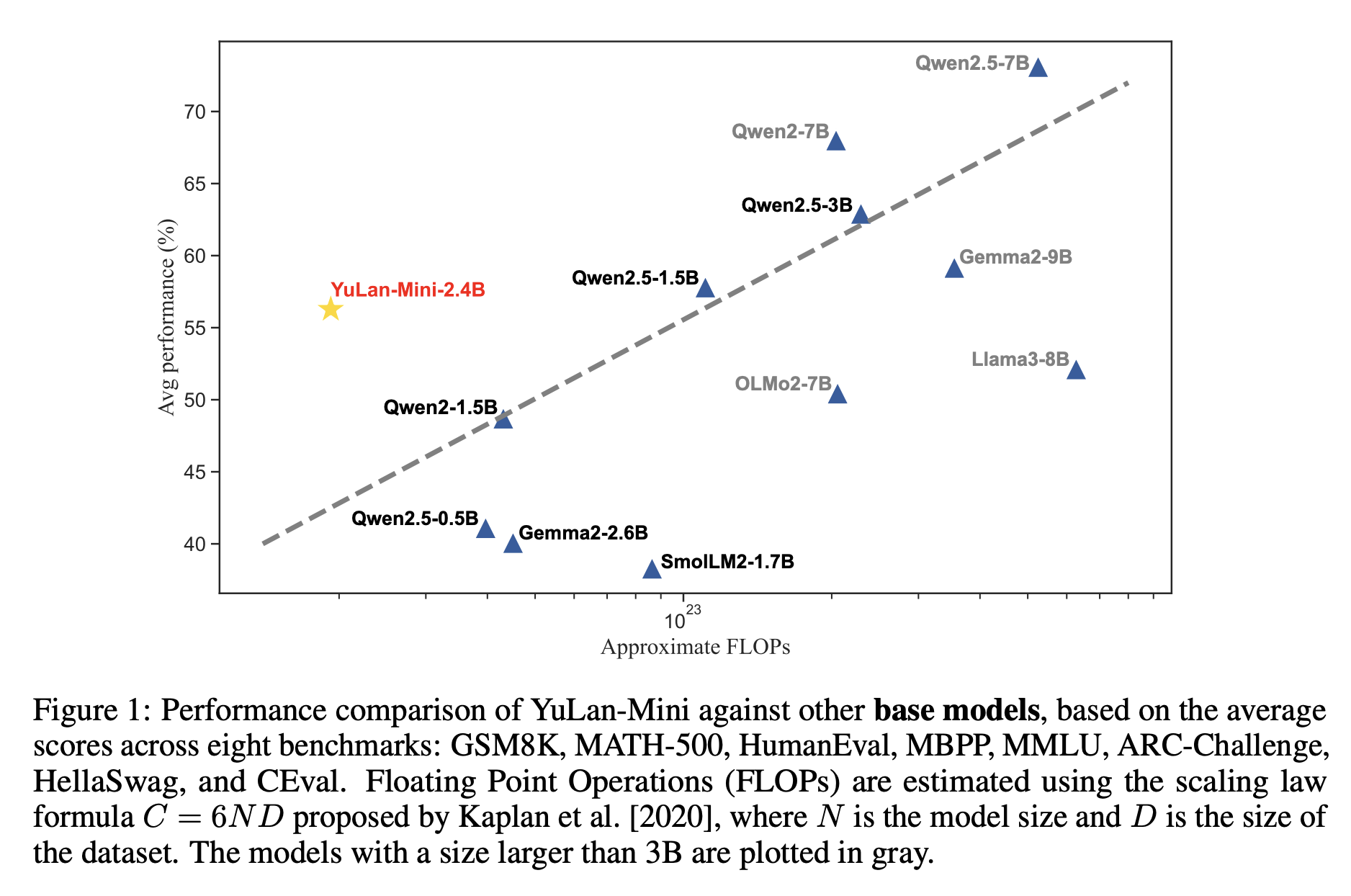
Researchers from the Gaoling School of Artificial Intelligence have developed YuLan-Mini, a language model with 2.42 billion parameters. This model enhances computational efficiency and performance by using data-efficient training methods. By utilizing publicly available data, YuLan-Mini achieves impressive results comparable to larger models.
Key Features of YuLan-Mini
- Efficient Architecture: Its decoder-only transformer design reduces parameter size and improves stability.
- Long Context Handling: With Rotary Positional Embedding (ROPE), it can manage contexts up to 28,672 tokens.
- Advanced Activation Functions: SwiGLU functions enhance data representation.
- Synthetic Data Usage: It supplements training data, improving outcomes without needing proprietary datasets.
Impressive Performance Metrics
YuLan-Mini scored 64.00 on HumanEval, 37.80 on MATH-500, and 49.10 on MMLU, showcasing its competitive edge. Its ability to handle both long and short texts effectively sets it apart from many existing models.
Key Takeaways
- YuLan-Mini’s data pipeline reduces the need for large datasets while ensuring quality learning.
- Systematic optimization techniques prevent common training issues.
- Extended context length enhances its capability for complex tasks.
- It achieves high performance with modest computational requirements.
- Integration of synthetic data improves training efficiency.
Conclusion
YuLan-Mini represents a significant advancement in efficient LLMs, delivering high performance with limited resources. Its innovative techniques pave the way for smaller research teams to make meaningful contributions to AI. With just 1.08 trillion tokens, it sets a new standard for resource-efficient models.
For more information, check out the Paper and GitHub Page. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. Join our 60k+ ML SubReddit for ongoing discussions.
Transform Your Business with AI
Stay competitive by leveraging YuLan-Mini for your business needs. Here’s how:
- Identify Automation Opportunities: Find customer interaction points that can benefit from AI.
- Define KPIs: Ensure measurable impacts from your AI initiatives.
- Select an AI Solution: Choose tools that fit your requirements and allow customization.
- Implement Gradually: Start with a pilot project, gather data, and expand wisely.
For AI KPI management advice, contact us at hello@itinai.com. For continuous insights, follow us on Telegram or @itinaicom.
Explore how AI can enhance your sales processes and customer engagement at itinai.com.

























