
Practical Solutions and Value of WavTokenizer: A Breakthrough Acoustic Codec Model
Revolutionizing Audio Compression
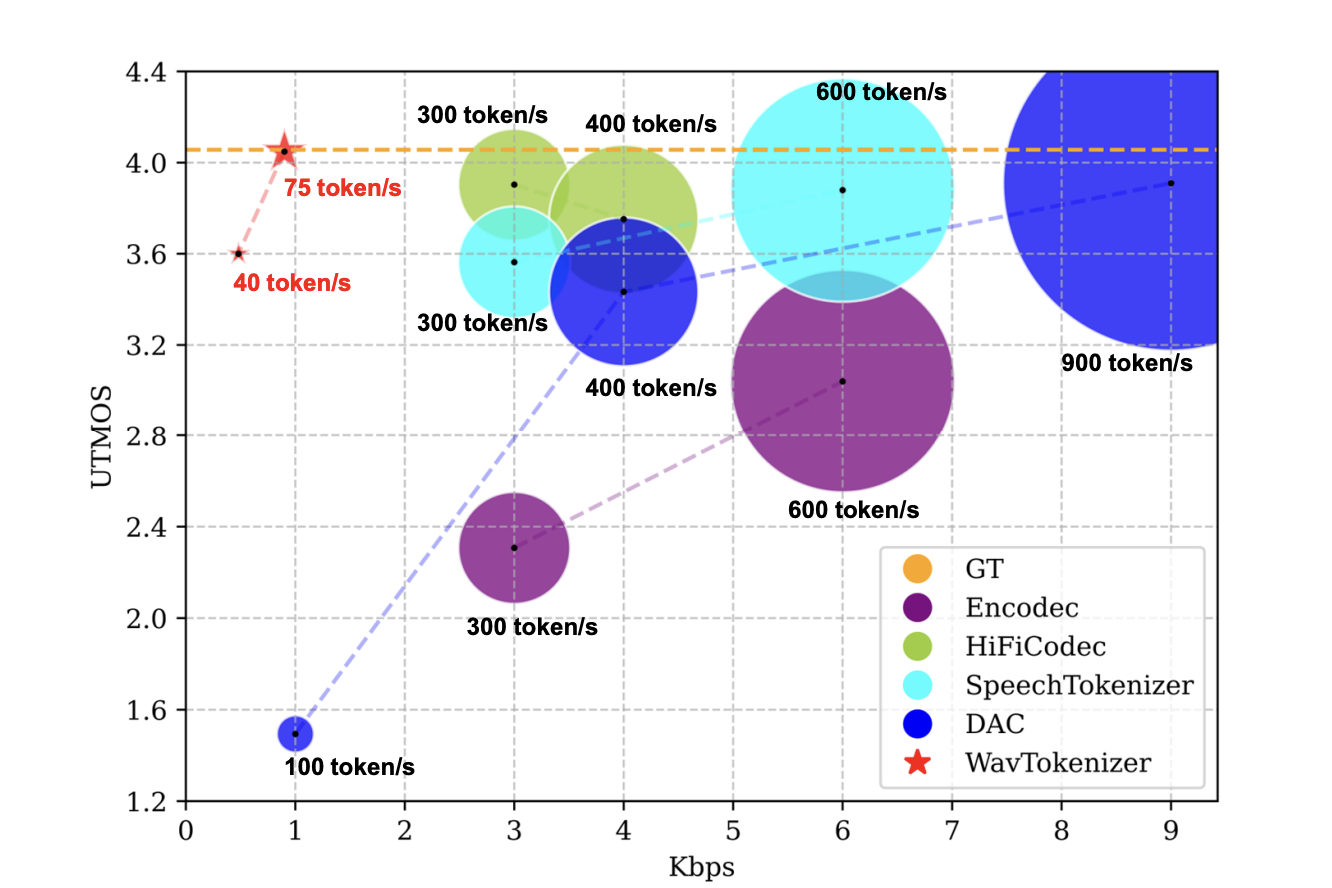
WavTokenizer is an advanced acoustic codec model that can quantize one second of speech, music, or audio into just 75 or 40 high-quality tokens. It achieves comparable results to existing models on the LibriTTS test-clean dataset while offering extreme compression.
Key Advantages
WavTokenizer offers extreme compression by reducing the layers of quantizers and the temporal dimension of the discrete codec, with only 40 or 75 tokens for one second of 24kHz audio. It also contains a broader VQ space, extended contextual windows, improved attention networks, a powerful multi-scale discriminator, and an inverse Fourier transform structure.
Unified Modeling Across Domains
Its architecture is designed for unified modeling across domains like multilingual speech, music, and audio. It has large, medium, and small versions trained on different amounts of data for various applications.
Outstanding Performance
WavTokenizer-small outperforms existing models and demonstrates effectiveness in audio reconstruction with minimal tokens. It performs comparably to other models on objective metrics like STOI, PESQ, and F1 score.
Future Impact
WavTokenizer has the potential to revolutionize audio compression and reconstruction across various domains and is positioned as a cutting-edge solution in the field of acoustic codec models.
























