
Introduction to VITA-1.5
The development of multimodal large language models (MLLMs) has opened new doors in artificial intelligence. However, challenges remain in combining visual, linguistic, and speech data effectively. Many MLLMs excel in vision and text but struggle with speech integration, which is crucial for natural conversations. Traditional systems that use separate speech recognition and text-to-speech modules can be slow and impractical for real-time use.
What is VITA-1.5?
Researchers from NJU, Tencent Youtu Lab, XMU, and CASIA have created VITA-1.5, a multimodal large language model that integrates vision, language, and speech through a smart three-stage training process. Unlike its earlier version, VITA-1.0, which relied on external modules, VITA-1.5 uses an end-to-end framework, making interactions faster and smoother.
Key Features of VITA-1.5
- Real-time Interaction: Combines vision and speech encoders with a speech decoder for near real-time communication.
- Progressive Training: Addresses conflicts between different data types while maintaining high performance.
- Open Source: The training and inference code is available to the public, encouraging further innovation.
Technical Details and Benefits
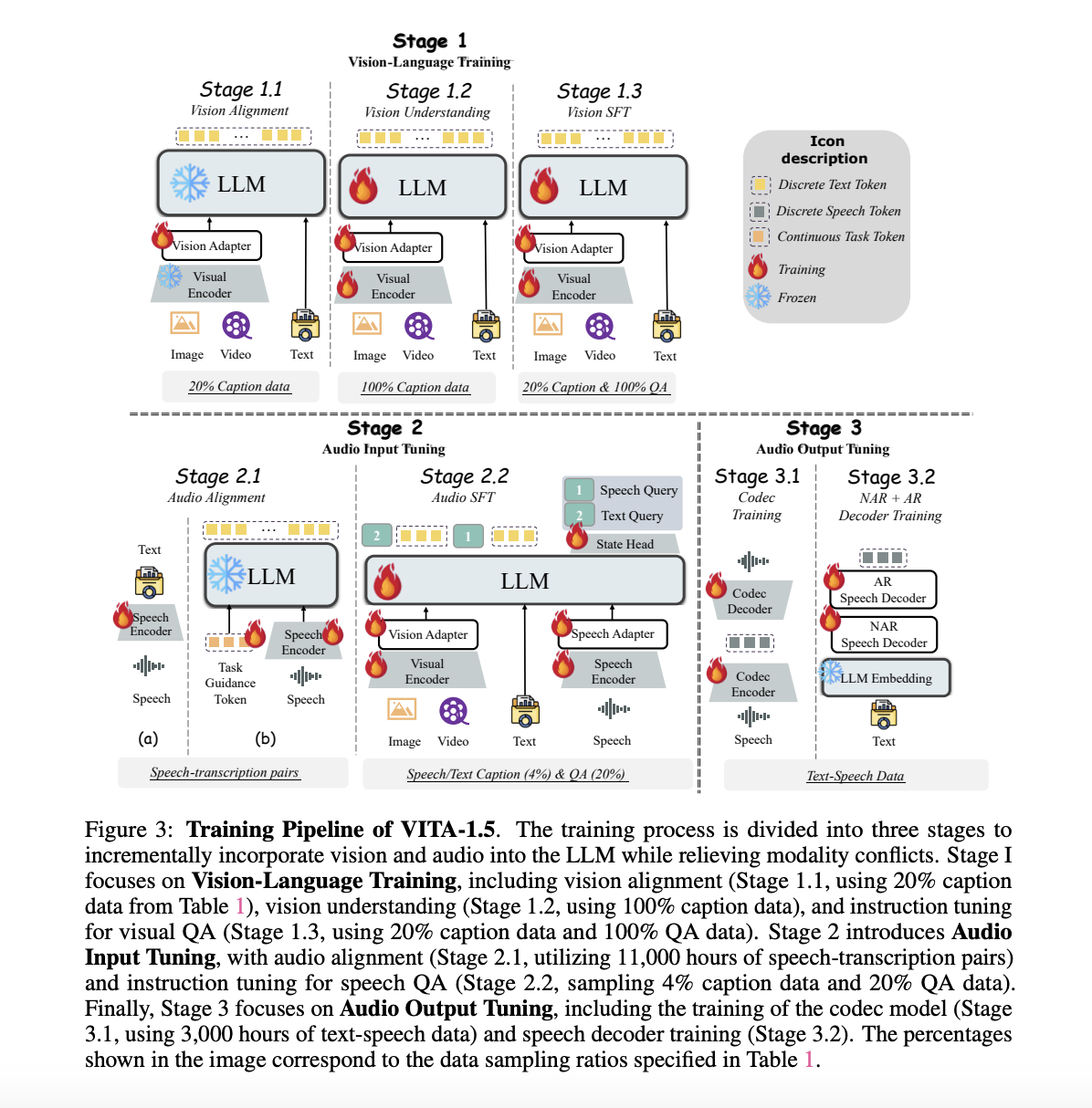
VITA-1.5 is designed for efficiency and capability. It uses advanced techniques for processing both visual and audio data, ensuring high-quality speech generation. The training process includes three main stages:
1. Vision-Language Training
This stage focuses on aligning visual data with language using descriptive captions and visual question answering tasks.
2. Audio Input Tuning
The audio encoder is aligned with the language model using speech-transcription data for effective audio processing.
3. Audio Output Tuning
The speech decoder is trained with paired text-speech data for coherent and seamless speech outputs.
Results and Insights
VITA-1.5 has shown strong performance across various benchmarks, competing well in image and video understanding tasks. It achieves results comparable to top models like GPT-4V and excels in speech tasks with low error rates in multiple languages. Importantly, it maintains visual reasoning capabilities even with audio processing.
Conclusion
VITA-1.5 offers a comprehensive solution for integrating vision, language, and speech, making it ideal for real-time applications. Its open-source nature allows researchers and developers to build and enhance its capabilities further. This model not only improves existing technologies but also paves the way for a more interactive future in AI.
Get Involved
Check out the Paper and GitHub Page. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. Join our 60k+ ML SubReddit for more insights.
Webinar Opportunity
Join our webinar to learn how to boost LLM model performance while ensuring data privacy.
Transform Your Business with AI
Stay competitive and leverage VITA-1.5 to redefine your work processes:
- Identify Automation Opportunities: Find key customer interaction points that can benefit from AI.
- Define KPIs: Ensure measurable impacts on business outcomes.
- Select an AI Solution: Choose tools that fit your needs and allow for customization.
- Implement Gradually: Start with a pilot project, gather data, and expand AI usage wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights, follow us on Telegram or Twitter.
Explore how AI can enhance your sales processes and customer engagement at itinai.com.























