
Understanding AI Systems That Learn and Adapt
Creating AI systems that learn from their environment involves building models that can adjust based on new information. One method, called In-Context Reinforcement Learning (ICRL), allows AI agents to learn through trial and error. However, it faces challenges in complex environments with multiple tasks, as it struggles to generalize from past experiences.
Current Approaches to Pre-Training AI Models
There are two main strategies for pre-training AI models for diverse tasks:
- Using All Available Data: This method relies on predicting future rewards, which can be unreliable in unpredictable situations.
- Imitating Expert Actions: This approach lacks adaptability because it does not consider real-time feedback.
Both methods have limitations in scaling and generalizing across different domains, making them less effective in real-world applications.
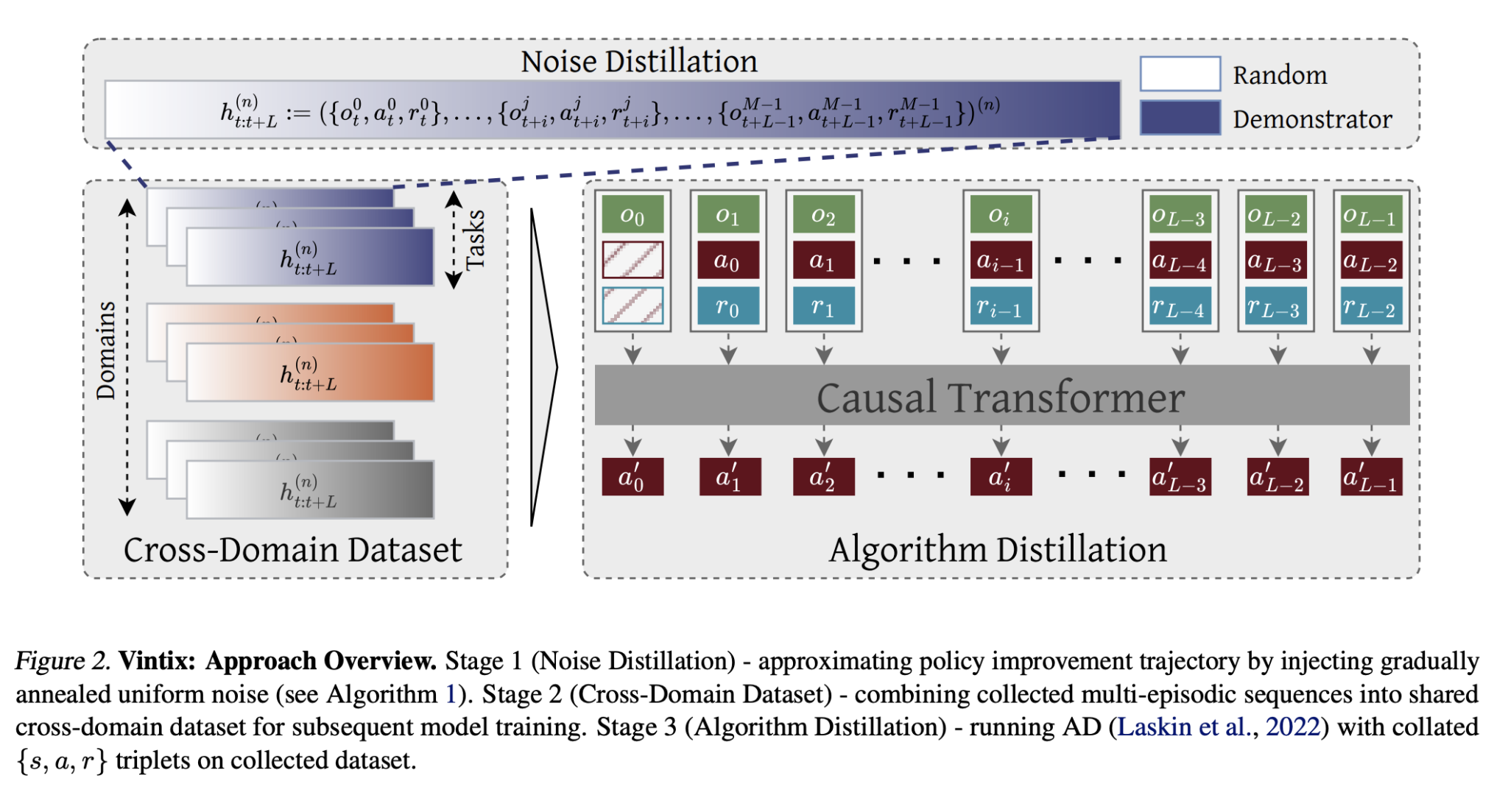
Introducing Vintix: A New AI Model
Researchers from Dunnolab AI have developed Vintix, which utilizes Algorithm Distillation for in-context reinforcement learning. This model differs from traditional methods by using a decoder-only transformer for predicting the next action, trained on learning histories from base algorithms. Key features include:
- Continuous Noise Distillation: This technique reduces noise in action selection and training across different tasks.
- Broad Data Utilization: Vintix employs data from 87 tasks across four benchmarks, allowing it to adapt to varied environments.
Technical Specifications
Vintix consists of a 300M-parameter model with 24 layers and an optimized tokenization strategy. It dynamically improves its performance over time without prior context. Initial results show strong generalization and policy refinement, making it effective for reinforcement learning tasks.
Performance and Adaptability
Vintix was evaluated for its ability to self-correct during inference. It showed improvements over related models, achieving near-demonstrator performance in various tasks:
- Improved by +32.1% in Meta-World and +13.5% in MuJoCo.
- Maintained strong performance even with unseen variations in tasks.
However, challenges remain in adapting to entirely new tasks, highlighting the need for further improvements in generalization.
Future Directions and Opportunities
The work on Vintix provides a foundation for future research in scalable, reward-driven reinforcement learning. If you’re looking to enhance your company’s AI capabilities, consider Vintix as a solution:
- Identify Automation Opportunities: Find key areas for AI integration.
- Define KPIs: Ensure measurable impacts on business outcomes.
- Select an AI Solution: Choose customizable tools that align with your needs.
- Implement Gradually: Start with pilot projects, gather data, and expand thoughtfully.
For AI KPI management advice, reach out to us at hello@itinai.com. For insights on leveraging AI, follow us on Telegram or Twitter @itinaicom.
Discover how AI can transform your sales processes and customer engagement at itinai.com.

























