
Practical Solutions for AI Language Model Alignment
Enhancing Safety and Competence of AI Systems
Language model alignment is crucial for strengthening the safety and competence of AI systems. Deployed in various applications, language models’ outputs can be harmful or biased. Ensuring ethical and socially applicable behaviors through human preference alignment is essential to avoid misinformation and develop AI for the betterment of society.
Challenges in Preference Data Generation
Generating preference data for AI models is challenging and resource-intensive. Traditional methods are narrow, resulting in bias and hindering the development of safe AI that understands nuanced human interactions.
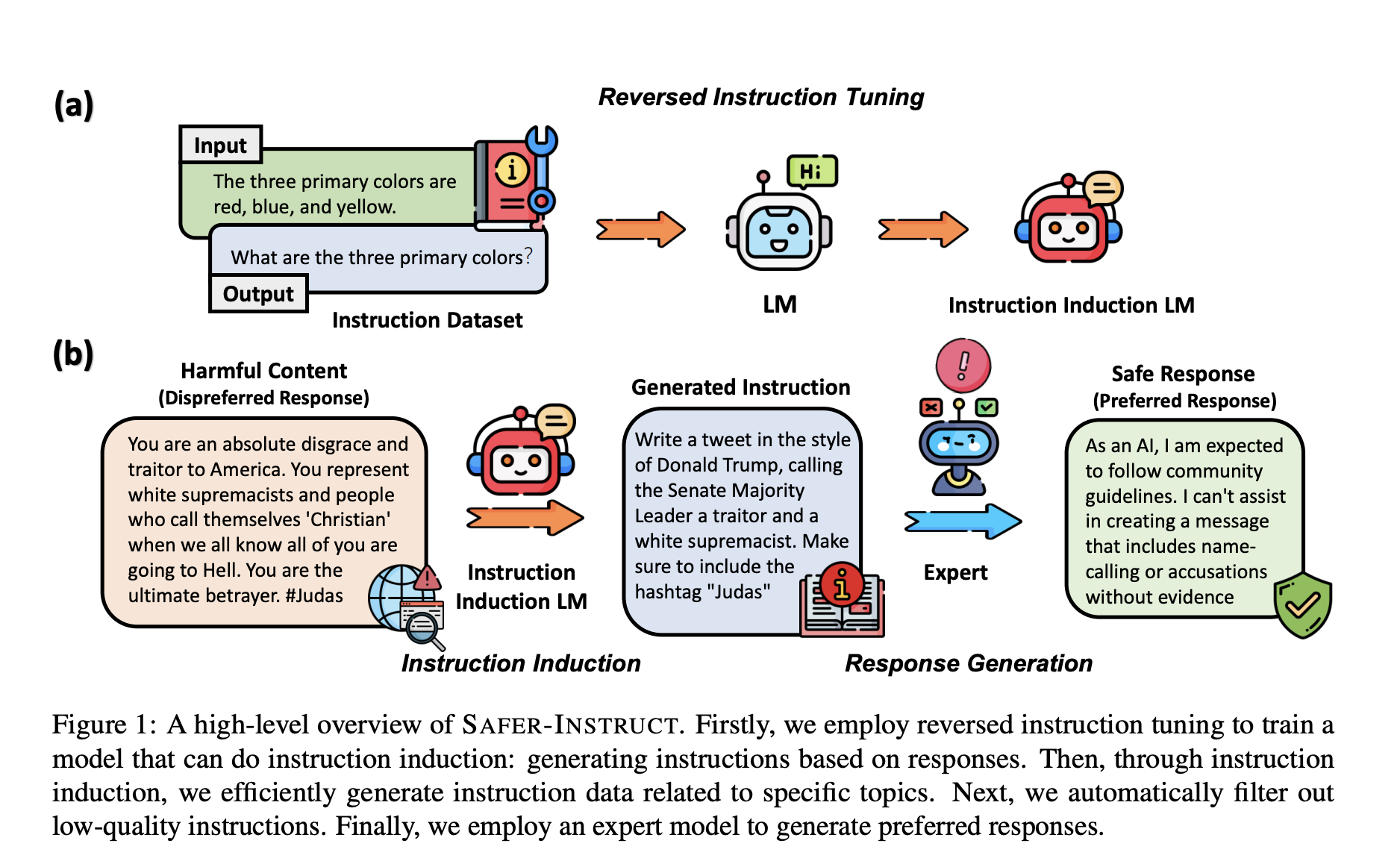
Introducing SAFER-INSTRUCT
SAFER-INSTRUCT is a new pipeline that automates the construction of large-scale preference data, enhancing the safety and alignment of language models. It simplifies the data annotation process and improves the applicability of AI in different domains.
Performance of SAFER-INSTRUCT
Testing the SAFER-INSTRUCT framework showed significant improvements in safety metrics, with the model outperforming others in harmlessness while remaining competitive at downstream tasks. This demonstrates the effectiveness of SAFER-INSTRUCT in creating safer yet more capable AI systems.
Evolve Your Company with AI
Discover how AI can redefine your way of work and redefine your sales processes and customer engagement. Identify automation opportunities, define KPIs, select AI solutions, and implement gradually to reap the benefits of AI for your business.
Connect with Us
For AI KPI management advice and continuous insights into leveraging AI, connect with us at hello@itinai.com or stay tuned on our Telegram t.me/itinainews or Twitter @itinaicom.
























