
TULIP: A New Era in AI Vision and Language Understanding
Introduction to Contrastive Learning
Recent advancements in artificial intelligence (AI) have significantly enhanced how machines link visual content to language. Contrastive learning models, which align images and text within a shared embedding space, play a crucial role in this evolution. These models are essential for applications such as zero-shot classification, image-text retrieval, and multimodal reasoning.
Challenges in Current Models
While these tools have advanced the integration of general concepts across different modalities, they still encounter difficulties in processing nuanced and spatially detailed visual information.
- Balancing Understanding and Recognition: Many existing models prioritize semantic alignment, often at the expense of high-resolution visual recognition. This leads to challenges in tasks requiring precise object location, depth understanding, and fine-grained texture recognition.
- Limitations of Current Models: Models such as CLIP and ALIGN have achieved impressive results but often overlook the detailed representations necessary for specialized tasks. For example, they may successfully identify objects but struggle with tasks like counting distinct items or identifying subtle differences.
The Introduction of TULIP
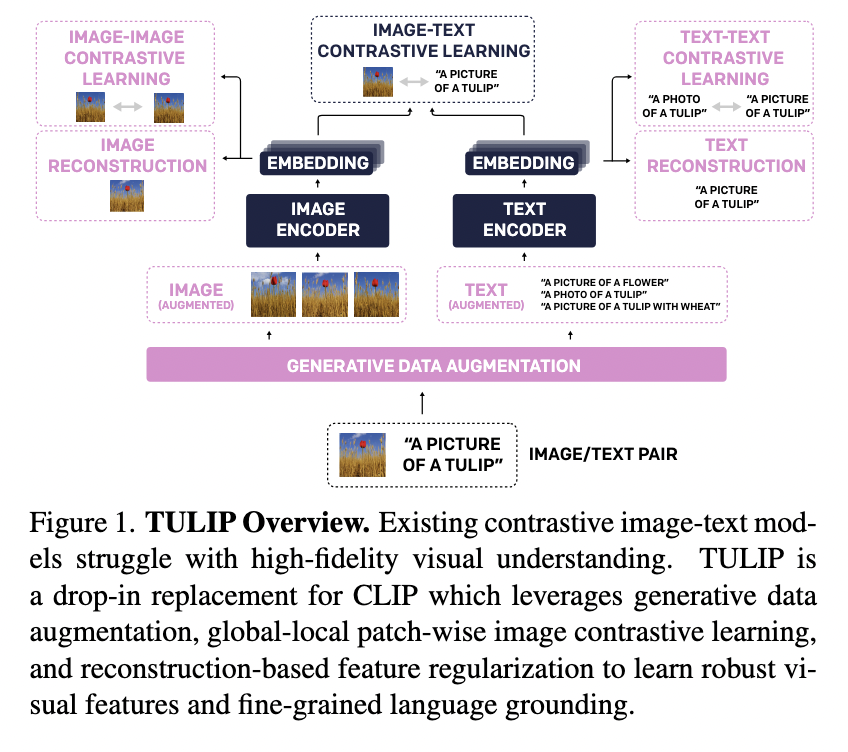
Researchers from the University of California, Berkeley, have introduced TULIP (Towards Unified Language-Image Pretraining) to overcome these limitations. TULIP is designed as an open-source, plug-in replacement for existing CLIP-like models, aiming to better integrate semantic alignment with high-fidelity visual representation.
Key Innovations of TULIP
TULIP employs several contrastive learning techniques alongside generative data augmentation and reconstruction-based regularization. This approach allows it to preserve both high-level semantic understanding and intricate visual details.
- Unified Contrastive Learning: TULIP incorporates image-image, image-text, and text-text contrastive learning strategies, supported by a module called GeCo (Generative Contrastive view augmentation).
- Generative Models: GeCo utilizes generative models to create challenging augmentations of images and text, producing both positive and negative contrastive pairs.
- Robust Encoding: The image encoder employs a vision transformer architecture with a masked autoencoder, while the text encoder uses advanced language models to paraphrase content.
Performance Metrics
TULIP demonstrates significant improvements across various benchmarks:
- ImageNet-1K Zero-Shot Classification: Achieved up to 89.6% accuracy, surpassing SigLIP by 2-3 percentage points.
- Few-Shot Classification on RxRx1: Performance increased from 4.6% to 9.8% over SigLIP.
- MMVP Benchmark: Improved performance over SigLIP by more than three times.
- Winoground Benchmark: First CIT model to achieve better-than-random results on group-based reasoning tasks.
Conclusion
The introduction of TULIP represents a substantial advance in resolving the trade-off between visual detail and semantic coherence in multimodal learning. By integrating generative augmentations and multi-view contrastive techniques into its framework, TULIP enhances the model’s ability to perform complex visual and linguistic reasoning. As such, it sets a new precedent for the development of future vision-language systems that can seamlessly merge broad understanding with fine-grained analysis.
For organizations looking to leverage artificial intelligence, exploring TULIP could lead to transformative improvements in how visual and textual data are processed and understood. Embracing such cutting-edge technology can enhance efficiency and drive better business outcomes.























