
Introduction to LADDER Framework
Large Language Models (LLMs) can significantly enhance their performance through reinforcement learning techniques. However, training these models effectively is still a challenge due to the need for vast datasets and human supervision. There is a pressing need for methods that allow LLMs to improve autonomously, without requiring extensive human input.
Challenges in Current Training Methods
The primary challenge in LLM training is to maintain an efficient and organized learning process. When models face tasks beyond their capacity, their performance suffers. Traditional reinforcement learning relies on curated datasets or human feedback, which is often resource-intensive. Moreover, LLMs find it difficult to grow systematically in their abilities without a structured approach to varying task difficulties.
Current Approaches to LLM Training
The prevalent techniques for training LLMs include:
- Supervised fine-tuning, which uses manually labeled data but can lead to overfitting.
- Reinforcement Learning from Human Feedback (RLHF), which is expensive and does not scale well.
- Curriculum Learning, which gradually increases task difficulty but still relies on predefined datasets.
These methods highlight the need for an autonomous learning framework that allows LLMs to enhance their problem-solving skills independently.
Introduction of the LADDER Framework
Researchers from Tufa Labs developed LADDER (Learning through Autonomous Difficulty-Driven Example Recursion) to address these limitations. LADDER enables LLMs to self-improve by generating and solving simpler variants of complex problems. This approach creates a natural difficulty gradient for structured self-learning.
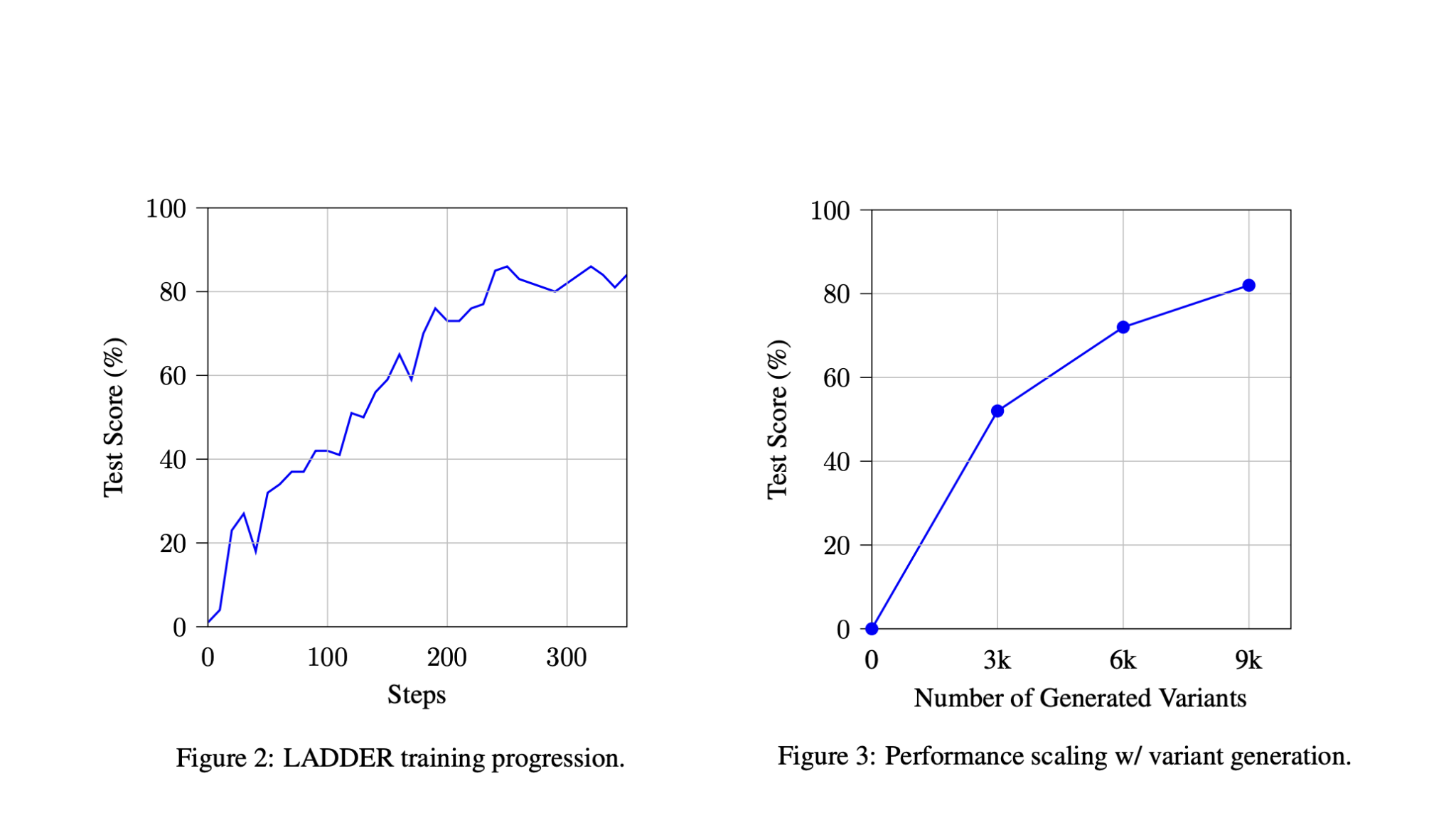
Results of Implementing LADDER
Tests on mathematical integration tasks showed that the Llama 3.2 model improved its accuracy from 1% to 82%, marking a significant advancement in reasoning capabilities. Larger models like Qwen2.5 7B achieved 73% accuracy in competitive examinations, outpacing previous models like GPT-4o.
Methodology Behind LADDER
LADDER utilizes a structured method that includes:
- Variant Generation: Producing easier versions of complex problems to create a structured difficulty gradient.
- Solution Verification: Using numerical methods for immediate feedback on solution correctness without human input.
- Reinforcement Learning: Employing Group Relative Policy Optimization (GRPO) to facilitate systematic learning.
With Test-Time Reinforcement Learning (TTRL), the model’s accuracy further improved during real-time problem-solving sessions.
Key Insights from the Research
- LADDER allows LLMs to self-improve by solving simpler problem variants.
- Llama 3.2 model accuracy rose from 1% to 82%, demonstrating effective self-learning.
- Qwen2.5 7B Deepseek-R1 surpassed GPT-4o, achieving notable accuracy.
- The approach eliminates the need for external datasets or supervision, making it cost-effective and scalable.
- Models trained with LADDER showed superior problem-solving skills compared to traditional methods.
Implications for Businesses
To leverage AI technologies effectively, businesses should:
- Explore automation opportunities in work processes.
- Identify key performance indicators (KPIs) to assess AI impact.
- Select customizable tools that align with business objectives.
- Start with small projects to collect data before expanding AI initiatives.
Contact Us
If you need help managing AI in your business, reach out to us at hello@itinai.ru or connect on Telegram, X, and LinkedIn.
“`























