
Practical Solutions and Value of TRUST-ALIGN Framework for Large Language Models
Enhancing Trustworthiness with TRUST-ALIGN
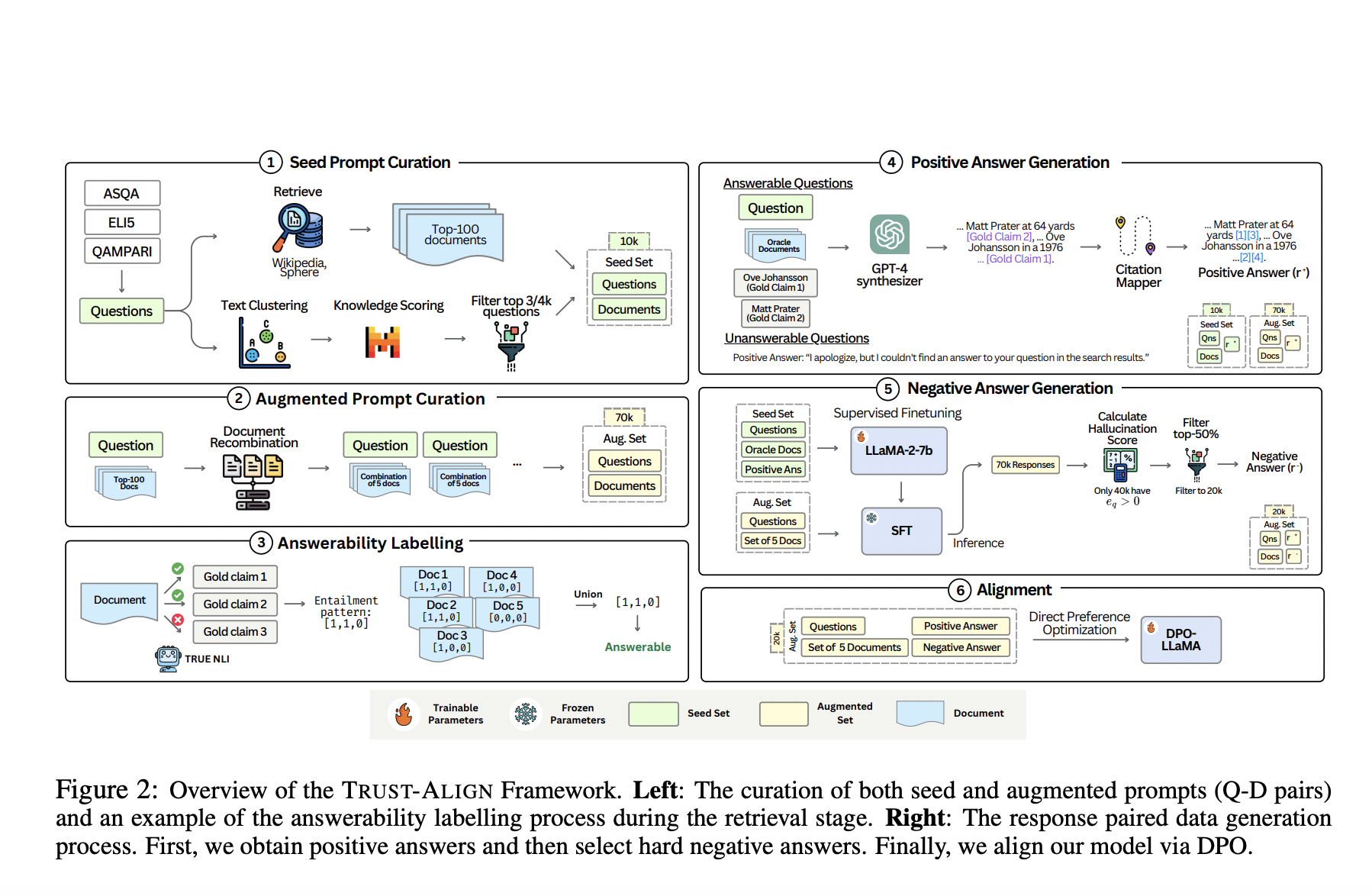
TRUST-ALIGN framework focuses on aligning large language models (LLMs) to generate accurate, document-supported responses, minimizing incorrect information.
Improving Model Performance
TRUST-ALIGN enhances model performance by optimizing behavior to provide grounded responses, leading to improved citation accuracy and reduced hallucinations.
Results and Benchmark Improvements
TRUST-ALIGN showed significant performance boosts across benchmark datasets, surpassing models like GPT-4 and Claude-3.5 Sonnet.
Benefits of TRUST-ALIGN
Increased refusal accuracy when documents are insufficient, improved citation quality, and overall trustworthiness of AI-generated responses.
Driving Real-World AI Applications
TRUST-ALIGN paves the way for more reliable AI systems by ensuring accuracy, well-cited information, and minimizing errors in various fields.
Don’t miss out on exploring the full paper and GitHub page for more details on this groundbreaking AI research!
For AI KPI management advice and insights on leveraging AI effectively, connect with us at hello@itinai.com or stay updated on Telegram t.me/itinainews and Twitter @itinaicom.






















