
This text reviews the current top open-source language models available.

A Review of the Top Open Source Language Models
If you’re looking to incorporate AI into your company and gain a competitive edge, you need to take advantage of the top 10 open source language models in 2023.
With these models, you can revolutionize the way you work and discover the untapped potential of AI. Here are some practical solutions and steps you can take to make the most of AI:
Introduction
Generative transformer models represent a breakthrough that has given rise to an era of generative AI. Since the launch of ChatGPT, the tech industry has witnessed an explosion of LLMs, especially open-source ones. Businesses of any size can tap into the power of these LLMs to create tailored solutions for their needs, whether it’s developing chatbots, generating content, or analyzing data. To help you navigate this landscape, we have crafted a curated list of the Top 10 Large Language Models in 2023. Let’s explore them!
The findings are summarized in the below table:
| Model Family Name | Created By | Sizes | Type | License |
| Llama 2 | Meta | 7B,
13B, 70B |
Foundation | Commercial |
| Falcon | Technology
Innovation Institute |
7B,
40B |
Foundation | Commercial |
| RedPajama | Together,
Ontocord.ai, ETH DS3Lab, CRFM Stanford Hazy Research group. |
3B, 7B | Foundation | Commercial |
| Mistral | Mistral AI | 7B | Foundation | Commercial |
| MPT | Mosaic ML | 7B | Foundation | Commercial |
| X Gen | Salesforce AI | 7B | Foundation | Commercial |
| Dolly V2 | Databricks | 12B | Foundation | Commercial |
| Zephyr | Hugging Face | 7B | Fine-Tuned | Commercial |
| Code Llama | Meta | 7B, 13B, 34B | Fine-Tuned | Commercial |
| WizardLM | Can Xu | 13B, 70B | Fine-Tuned |
Llama 2
Llama 2 is a family of large language models released by Meta. Llama 2 builds upon the success of Llama 1 and incorporates several improvements to enhance its performance and safety. These models are designed to excel in complex reasoning tasks across various domains, making them suitable for research and commercial use.
Llama-2 is trained on a large corpus of publicly available data and fine-tuned to align with human preferences, ensuring usability and safety. The models are optimized for dialogue use cases and are available in a range of parameter sizes, including 7B, 13B, and 70B.
Llama 2-Chat is a fine-tuned version of Llama-2 models that are optimized for dialogue use cases. These models are specifically designed to generate human-like responses to natural language input, making them suitable for chatbot and conversational AI applications.
In addition to the standard Llama-2 models, the Llama 2-Chat models are also fine-tuned on a set of safety and helpfulness benchmarks to ensure that they generate appropriate and useful responses. This includes measures to prevent the models from generating offensive or harmful content and to ensure that they provide accurate and relevant information to users.
The context window length in the Llama-2 model is 4096 tokens. This is an expansion from the context window length of the 2048 tokens used in the previous version of the model, Llama-1. The longer context window enables the model to process more information, which is particularly useful for supporting longer histories in chat applications, various summarization tasks, and understanding longer documents.
Try out the chat versions of Llama 2 models here: Llama-2 70 b Chat, Llama-2 13 B Chat, Llama-2 7B chat
Falcon
Falcon is a family of state-of-the-art language models created by the Technology Innovation Institute. The Falcon family is composed of two base models: Falcon-40B and Falcon-7B and was trained on the RefinedWeb dataset.
The architecture of Falcon was optimized for performance and efficiency. Combining high-quality data with these optimizations, Falcon significantly outperforms GPT-3 for only 75% of the training compute budget and requires a fifth of the compute at inference time.
The Falcon models incorporate an interesting feature called multi-query attention. Unlike the traditional multi-head attention scheme, which has separate query, key, and value embeddings per head, multi-query attention shares a single key and value across all attention heads. This enhances the scalability of inference, significantly reducing memory costs and enabling optimizations like statefulness. The smaller K, V-cache during autoregressive decoding contributes to these benefits.
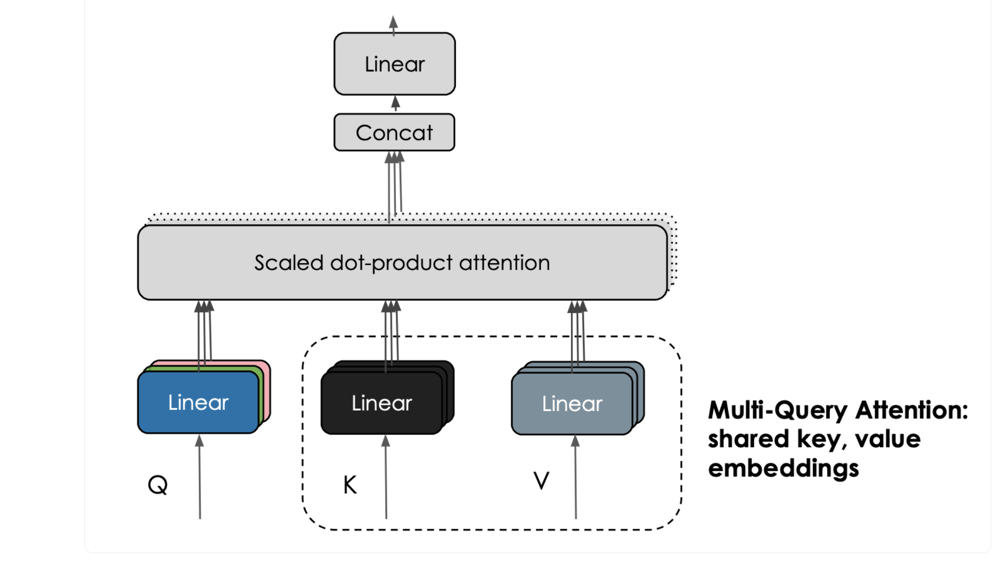
Falcon also has the Instruct versions, Falcon-40b-Instruct and Falcon-7b-Instruct which are fine-tuned on instructions and conversational data, they thus lend better to popular assistant-style tasks.
Try out the models here: Falcon-40b-Instruct, Falcon-7b-Instruct
RedPajama
RedPajama is a collaborative project involving Together and leaders from the open-source AI community including Ontocord.ai, ETH DS3Lab, AAI CERC, Université de Montréal, MILA – Québec AI Institute, Stanford Center for Research on Foundation Models (CRFM), Stanford Hazy Research research group and LAION.
RedPajama Base Models: The 3 billion parameter and 7 billion parameter base models form the foundation of the RedPajama models. They were developed based on the Pythia architecture and designed to excel in different tasks
Two variations of RedPajama-3b-base are RedPajama-INCITE-Chat-3B-v1 and RedPajama-INCITE-Instruct-3B-v1. The RedPajama-INCITE-Chat-3B-v1 model is optimized for conversational AI tasks, adept at generating human-like text in a conversational context. On the other hand, the RedPajama-INCITE-Instruct-3B-v1 model is designed to follow instructions effectively, making it ideal for understanding and executing complex instructions.
Similarly, the 7b base variant has RedPajama-INCITE-Chat-7B-v1 and RedPajama-INCITE-Instruct-7B-v1.
Try out the model here: RedPajama-INCITE-Chat-7B-v1
Mistral 7B
Mistral 7B is the language model from Mistral AI. It represents a significant leap in natural language understanding and generation. The model is released under the Apache 2.0 license, allowing its unrestricted usage and it utilizes Grouped-query attention (GQA) to enable faster inference, making it suitable for real-time applications. Additionally, Sliding Window Attention (SWA) is employed to handle longer sequences efficiently and economically.
Mistral 7B surpasses the performance of Llama 2 13B on all benchmark tasks and excels on many benchmarks compared to Llama 34B. It also demonstrates competitive performance with CodeLlama-7B on code-related tasks while maintaining proficiency in English language tasks.
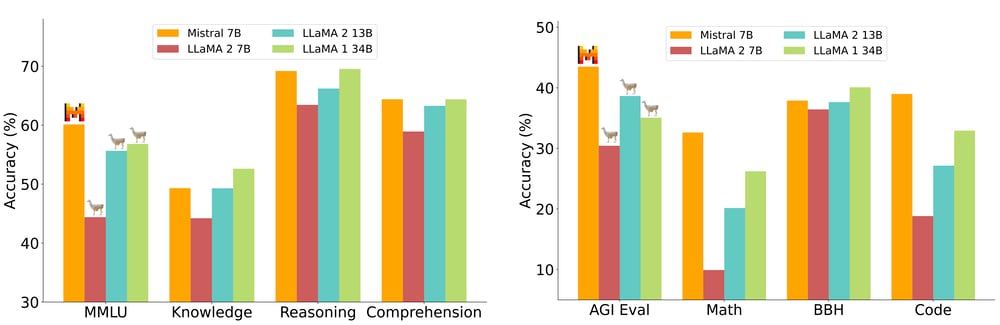
Mistral 7B also excels not only in code-related tasks, approaching CodeLlama 7B performance, but also remains highly proficient in various English language tasks.
The model can be easily fine-tuned on any task. Mistral 7B Instruct is the model fine-tuned for chat, which outperforms Llama 2 13B chat.
Try out the model here: Mistral 7B Instruct
MPT 7B
MPT is an open-source transformer model series designed by MosaicML. The models are trained on 1T tokens that can handle extremely long inputs and are also optimized for fast training and inference.
There are three fine-tuned models in addition to the base MPT-7B which are MPT-7B-Instruct, MPT-7B-Chat, and MPT-7B-StoryWriter-65k+. Here are more details of these models:
- MPT-7B Base: MPT-7B Base is a decoder-style transformer with 6.7B parameters. It was trained on 1T tokens of text and code that was curated by MosaicML’s data team. This base model includes FlashAttention for fast training and inference and ALiBi for finetuning and extrapolation to long context lengths.
- MPT-7B-StoryWriter-65k+: MPT-7B-StoryWriter-65k+ is a model designed to read and write stories with super-long context lengths. It was built by finetuning MPT-7B with a context length of 65k tokens on a filtered fiction subset of the books3 dataset. At inference time, thanks to ALiBi, MPT-7B-StoryWriter-65k+ can extrapolate even beyond 65k tokens, and we have demonstrated generations as long as 84k tokens on a single node of A100-80GB GPUs.
- MPT-7B-Instruct: MPT-7B-Instruct is a model for short-form instruction following. Built by finetuning MPT-7B on a dataset we also release, derived from Databricks Dolly-15k and Anthropic’s Helpful and Harmless datasets.
- MPT-7B-Chat: MPT-7B-Chat is a chatbot-like model for dialogue generation. Built by finetuning MPT-7B on ShareGPT-Vicuna, HC3, Alpaca, Helpful and Harmless, and Evol-Instruct datasets.
Try out the Model here: MPT-7B-Instruct
XGen 7B
XGen 7B is a series of 7B LLMs from Salesforce AI. The XGen-7b models are trained using JaxFormer, which leverages efficient training of LLMs under both data and model parallelism optimized for TPU-v4 hardware.
XGen-7B-4K-base which is trained for 800B tokens with a sequence length of 2k tokens first, then for another 400B tokens (total 1.2T tokens) with 4k and XGen-7B-8K-base initialized with XGen-7B-4K-base and further trained for 300B more tokens (total 1.5T tokens) with 8K sequence length.
XGen-7B also has 4K and 8K instruct versions which are fine-tuned on public domain instructional data including databricks-dolly-15k, oasst1, Baize and GPT-related datasets.
The XGEN-7B-8K-instruct model is trained on up to 8K sequence length for up to 1.5 trillion tokens, making it suitable for long sequence modeling tasks such as text summarization, dialogue generation, and code generation.
Try out 8K Instruct model here: X-Gen-7B-8K-instruct
Dolly V2
The Dolly V2 model is a 12B parameter language model developed by Databricks, built upon the EleutherAI Pythia model family. It is designed to follow instructions provided in natural language and generate responses accordingly. Unlike its predecessor, Dolly 2.0 is an open-source model, fine-tuned on a high-quality human-generated instruction dataset called “databricks-dolly-15k” licensed for research and commercial use.
The databricks-dolly-15k dataset contains 15,000 high-quality human-generated prompt/response pairs specifically designed for instruction tuning large language models.
The primary objective of this model is to exhibit human-like interactivity while adhering to provided instructions.
Try out the Dolly V2 here: Dolly V2-12 B
Zephyr-7B-Alpha
Zephyr is a series of language models designed to serve as helpful assistants. Zephyr-7B-alpha is the first model in this series and represents a fine-tuned version of Mistral 7B. It was trained on a combination of publicly available and synthetic datasets using Direct Preference Optimization (DPO) to improve its performance. The model outperformed Llama-2-70B Chat on MT Bench.
Zephyr-7B-alpha was initially fine-tuned on a variant of the UltraChat dataset, which includes synthetic dialogues generated by ChatGPT. Further alignment was achieved using huggingface TRL’s DPOTrainer on the openbmb/UltraFeedback dataset, consisting of prompts and model completions ranked by GPT-4. This allows the model to be used for chat applications.
Zephyr-7B-alpha has not been aligned to human preferences using techniques like Reinforcement Learning from Human Feedback (RLHF), nor has it undergone in-the-loop filtering of responses like ChatGPT. As a result, it can produce outputs that may be problematic, especially when intentionally prompted.
Try out the model here: Zephyr-7B-Alpha
Code Llama
Code Llama is a state-of-the-art LLM from Meta capable of generating code, and natural language about code, from both code and natural language prompts. It can also be used for code completion and debugging. It supports many of the most popular languages being used today, including Python, C++, Java, PHP, Typescript (Javascript), C#, and Bash.
Code Llama is a code-specialized version of Llama 2 that was created by further training Llama 2 on its code-specific datasets. Code Llama features enhanced coding capabilities, built on top of Llama 2.
Code Llama is available in three sizes 7B, 13B, and 34B parameters respectively. Each of these models is trained with 500B tokens of code and code-related data.
Additionally, there are two additional variations which are fine-tuned versions of Code Llama which are Code Llama-Python which is fine-tuned on 100B tokens of Python code and Code Llama-Instruct which is an instruction fine-tuned and aligned variation of Code Llama.
Try out the Code Llama Instruct models: Code Llama-34b-Instruct, Code Llama-13b-Instruct, Code Llama-7b-Instruct
WizardLM
WizardLM models are language models fine-tuned on the Llama2-70B model using Evol Instruct methods. Despite WizardLM lagging behind ChatGPT in some areas, the findings suggest that fine-tuning LLMs with AI-evolved instructions holds great promise for enhancing these models.
Evol-Instruct is a method for creating a vast amount of instruction data with varying complexity levels using LLMs. It begins with a set of initial instructions and progressively transforms them into more intricate forms. Evol-Instruct avoids the manual crafting of open-domain instruction data which is a time-consuming and labor-intensive process.
There are different versions of WizardLM models, WizardLM-70B, WizardLM-13B and WizardLM-7B which are fine-tuned on AI-evolved instructions using the Evol+ approach. The model is pre-trained on a large corpus of text data and fine-tuned on the Llama-2 dataset to generate high-quality responses to complex instructions.
Try out the WizardLM models here: Wizard LM 70B, Wizard LM 13B
LLM Battleground
Compare various LLMs at once and see which works best for your usecase. LLM Battleground Module allows you to run and compare numerous LLMs concurrently, providing an unprecedented platform for comparison. The module greatly simplifies the process of LLM selection with features like centralized access, simultaneous testing, real-time comparison, and communal testing insights.
Try out the Module here: LLM Battleground Module
Identify Automation Opportunities:
Find the key points in your customer interactions that can benefit from AI. By automating these processes, you can enhance efficiency and provide a better customer experience.
Define KPIs:
To ensure that your AI efforts have measurable impacts on your business outcomes, establish key performance indicators (KPIs). This allows you to track the effectiveness of your AI solutions and make data-driven decisions.
Select an AI Solution:
Choose AI tools that align with your specific needs and can be customized to your business. By selecting the right solution, you can maximize the value you get from AI.
Implement Gradually:
Start your AI journey with a small-scale pilot project. Gather data and insights from this initial implementation, and then gradually expand your AI usage as you gain confidence and experience.
For AI KPI management advice and more information, connect with us at hello@itinai.com. To stay updated on the latest AI insights and news, follow us on Telegram at t.me/itinainews or on Twitter @itinaicom.
Spotlight on a Practical AI Solution
Consider the AI Sales Bot from itinai.com/aisalesbot. This solution is designed to automate customer engagement round the clock and manage interactions across all stages of the customer journey.
Discover how AI can redefine your sales processes and customer engagement. Explore our AI solutions at itinai.com.


























