
Revolutionizing AI Inference with Together AI
Unveiling the Next Generation of AI Performance
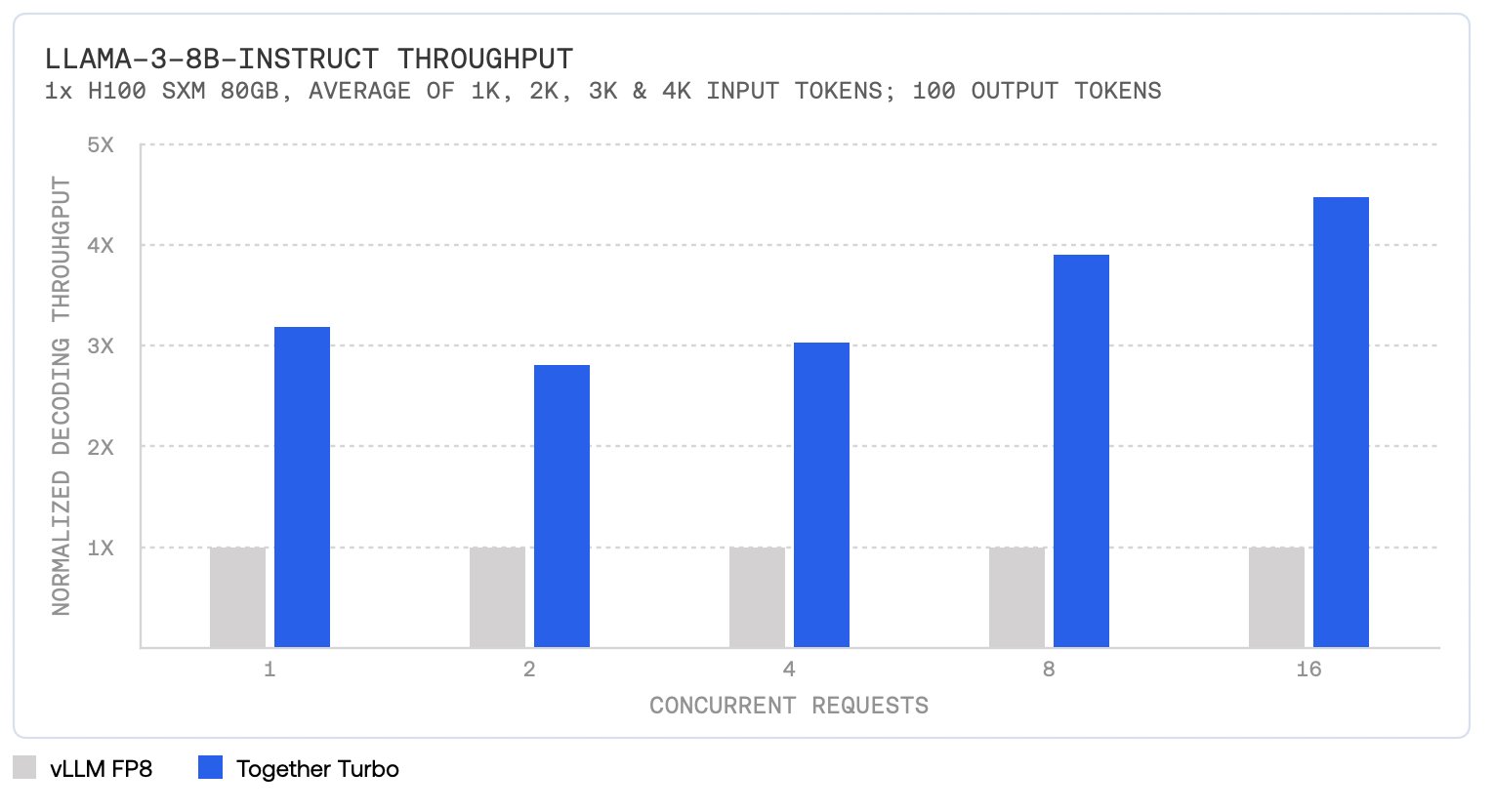
Together AI has introduced a groundbreaking advancement in AI inference with its new inference stack. The stack offers decoding throughput four times faster than open-source vLLM and surpasses leading commercial solutions like Amazon Bedrock, Azure AI, Fireworks, and Octo AI by 1.3x to 2.5x.
Practical Solutions and Value
The Together Inference Engine, capable of processing over 400 tokens per second on Meta Llama 3 8B, integrates the latest innovations from Together AI, including FlashAttention-3, faster GEMM and MHA kernels, and quality-preserving quantization, as well as speculative decoding techniques. This advancement provides enterprises with a balance of performance, quality, and cost-efficiency.
Key Components of the New Release
- Together Turbo Endpoints: These endpoints offer fast FP8 performance while maintaining quality that closely matches FP16 models. They have outperformed other FP8 solutions on AlpacaEval 2.0 by up to 2.5 points.
- Together Lite Endpoints: Utilizing multiple optimizations, these endpoints provide the most cost-efficient and scalable Llama 3 models with excellent quality relative to full-precision implementations.
- Together Reference Endpoints: These provide the fastest full-precision FP16 support for Meta Llama 3 models, achieving up to 4x faster performance than vLLM.
Leading Performance and Cost Efficiency
The Together Inference Engine integrates numerous technical advancements, ensuring leading performance without sacrificing quality. Together Turbo endpoints, in particular, provide up to 4.5x performance improvement over vLLM on Llama-3-8B-Instruct and Llama-3-70B-Instruct models. Additionally, the cost efficiency of Together Turbo and Lite endpoints offers significant cost reductions compared to other solutions in the market.
Embracing Cutting-Edge Innovations
The Together Inference Engine continuously incorporates cutting-edge innovations from the AI community and Together AI’s in-house research. Recent advancements like FlashAttention-3 and speculative decoding algorithms highlight the ongoing optimization efforts, offering the flexibility to scale applications with the performance, quality, and cost-efficiency that modern businesses demand.
Elevate Your Company with AI
If you want to evolve your company with AI and stay competitive, Together AI’s Revolutionary Inference Stack sets new standards in generative AI performance. Discover how AI can redefine your way of work and redefine your sales processes and customer engagement.
Connect with Us
For AI KPI management advice and continuous insights into leveraging AI, connect with us at hello@itinai.com. Stay tuned on our Telegram or Twitter for more insights.
Discover how AI can redefine your sales processes and customer engagement. Explore solutions at itinai.com.



























