
TEAL: Revolutionizing Large Language Model Efficiency
Introduction
Together AI has introduced TEAL, a groundbreaking technique that optimizes large language model (LLM) inference by achieving significant activation sparsity without the need for training. TEAL offers practical solutions to enhance model efficiency and minimize performance degradation in resource-constrained environments.
The Challenge in Large Language Models
LLMs require extensive memory resources for inference, leading to bottlenecks in traditional processes. TEAL addresses this challenge by introducing activation sparsity, a method that reduces model size without compromising performance.
The Concept Behind TEAL
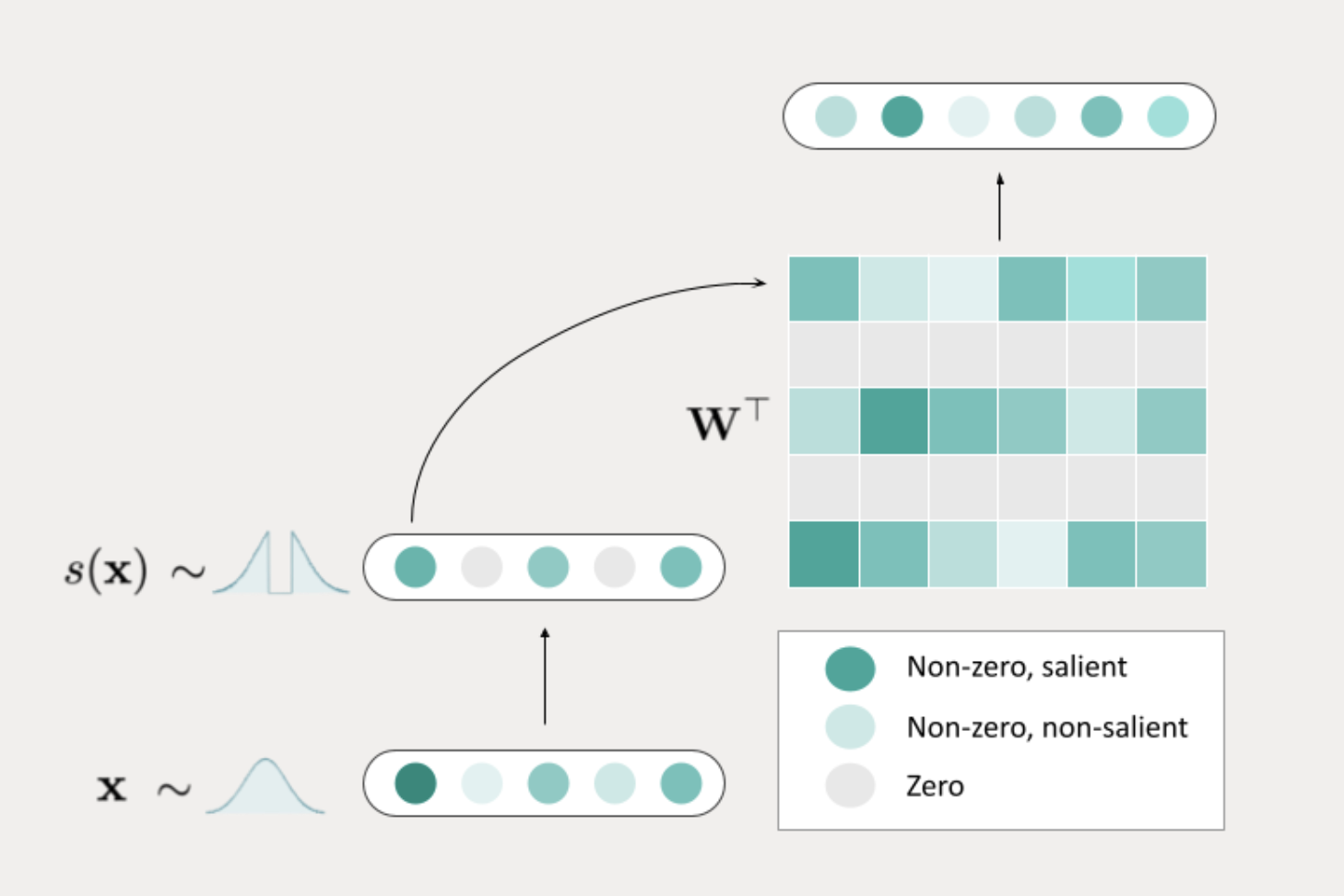
TEAL sparsifies activation in LLMs through magnitude pruning, achieving 40-50% model-wide activation sparsity with minimal impact on performance. It optimizes sparsity across all tensors in the model, reducing memory bandwidth and improving processing times.
Technical Implementation of TEAL
TEAL optimizes sparsity at the transformer block level, achieving near-zero performance degradation at 25% sparsity and minimal degradation at 40-50% sparsity. Its approach to sparsifying weight matrices results in significant speed-ups in single-batch decoding, making it ideal for real-world applications.
Hardware and Quantization Compatibility
TEAL complements quantization methods, enhancing hardware efficiency and performing well on GPU hardware. It is suitable for resource-constrained environments and large-scale inference settings, delivering improved memory usage and reduced latency.
Applications and Future Potential
TEAL accelerates inference in edge devices, excels in low-batch settings, and enhances the efficiency of large fleets of GPUs and models. It offers practical solutions for optimizing memory usage and improving processing speeds, especially in resource-constrained environments.
Conclusion
TEAL presents a simple and effective solution to optimize LLMs, offering enhanced efficiency and minimal degradation. It is a powerful tool for improving ML models’ efficiency in resource-constrained environments and large-scale inference settings.
























