
Transforming AI with Tina: Cost-Effective Reinforcement Learning
Introduction
Despite significant advancements in language models (LMs), achieving effective multi-step reasoning remains a challenge, particularly in areas like scientific research and strategic planning. Traditional methods, such as supervised fine-tuning (SFT), rely heavily on high-quality reasoning traces, which can be expensive and often lead to superficial learning. However, researchers have developed innovative strategies to enhance reasoning capabilities in a more cost-effective manner.
Challenges in Current Approaches
Current reinforcement learning (RL) methods are typically resource-intensive and complex. This raises the critical question: how can organizations develop reasoning-capable models without incurring high costs?
Alternatives to Traditional Methods
- Lightweight imitation learning
- Scalable instruction tuning
- Simplified RL techniques
Recent innovations like Group Relative Policy Optimization (GRPO) have also emerged, enhancing the efficiency of RL training. Additionally, Low-Rank Adaptation (LoRA) methods allow for updates to only a small subset of model parameters, significantly reducing computational demands while maintaining reasoning capabilities.
The Introduction of Tina
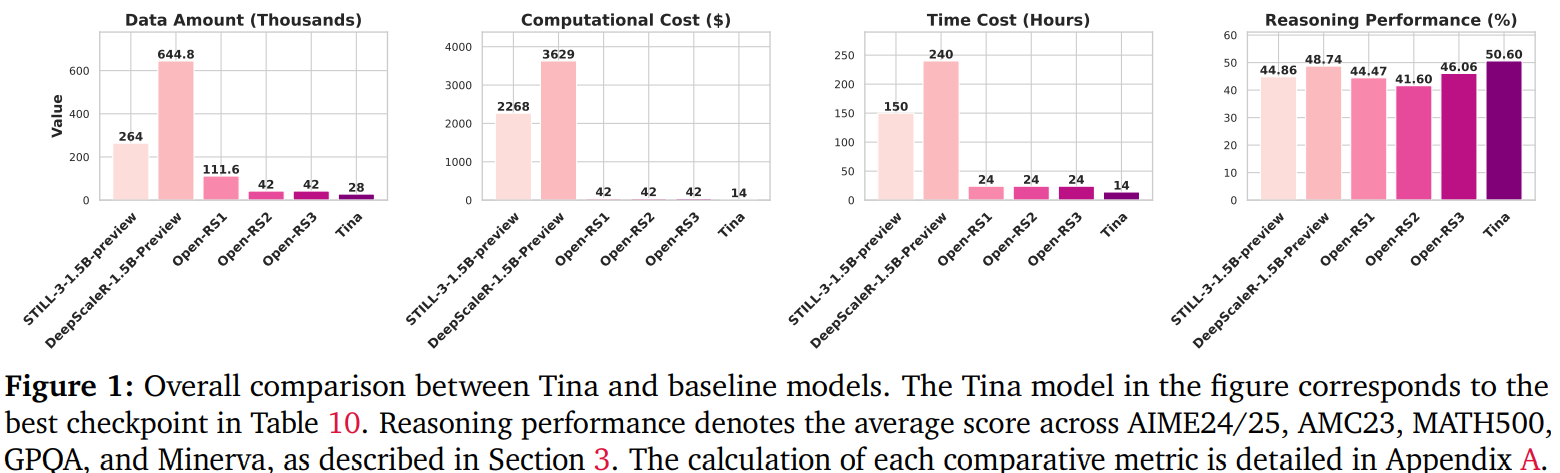
Researchers from the University of Southern California have introduced Tina, a series of compact reasoning models that deliver strong performance at a fraction of traditional costs. By applying RL enhanced with LoRA on a 1.5 billion parameter base model, Tina models demonstrate remarkable reasoning performance, achieving over a 20% improvement and a 43.33% Pass@1 accuracy on AIME24, with a post-training cost of just $9.
Efficient Model Training
Tina models were developed using public datasets and based on setups from existing models like STILL-3 and DeepScaleR. Training was conducted using minimal resources, averaging under $100 per experiment, making it an accessible platform for research in reasoning.
Methodology and Evaluation
To ensure reliable comparisons, the researchers employed consistent evaluation setups using the LightEval framework and vLLM engine. Six reasoning benchmarks, including AIME 24/25 and MATH 500, were utilized. Results indicated that Tina models frequently outperformed larger models despite reduced training time, highlighting the effectiveness of their approach.
Key Findings
- Smaller, high-quality datasets led to better performance.
- Appropriate learning rates and moderate LoRA ranks positively influenced outcomes.
- Careful selection of RL algorithms was crucial for success.
Conclusion
Tina represents a groundbreaking development in lightweight reasoning models, achieving impressive performance with minimal computational resources. By utilizing LoRA during reinforcement learning, Tina models not only compete with larger counterparts but also do so at an exceptionally low cost. While there are limitations, such as model scale and diversity in reasoning tasks, the open-sourced nature of Tina encourages further exploration and research in the field.
Next Steps for Businesses
Organizations looking to leverage AI for enhanced reasoning can take several practical steps:
- Identify processes that can be automated with AI.
- Determine key performance indicators (KPIs) to assess the impact of AI investments.
- Select tools that align with business objectives and allow for customization.
- Start with a pilot project to gather data and evaluate effectiveness before scaling.
For expert guidance on integrating AI into your business strategy, please contact us at hello@itinai.ru or follow us on our social media platforms.



























