
Understanding the Importance of Scientific Metadata
Scientific metadata is crucial for research literature, as it enhances the findability and accessibility of scientific documents. By using metadata, papers can be indexed and linked effectively, creating a vast network that researchers can navigate easily. Despite its past neglect, especially in fields like social sciences, the research community now acknowledges metadata’s significance.
Advancements in Metadata Automation
Recent improvements in metadata automation have been driven by advanced techniques in natural language processing (NLP) and computer vision. Although NLP has made great strides in extracting metadata, challenges remain, particularly for small and mid-sized publications with diverse formats.
Innovative Research Solutions
Researchers at the Fraunhofer Institute tackled the issue by exploring various methods for extracting metadata from scientific PDFs. They employed a mix of traditional and cutting-edge techniques:
- Conditional Random Fields
- BiLSTM with BERT representations
- Multimodal methods and TextMap techniques
These methods addressed the limitations of typical models that rely on consistent data structures, allowing for better handling of varied document formats.
Creating Labeled Datasets
To support their research, the team created two challenging labeled datasets for training tools based on deep neural networks (DNNs). The datasets included:
- SSOAR-MVD: 50,000 samples from predefined templates.
- S-PMRD: Data derived from the Semantic Scholar Open Research Corpus.
Modeling and Results
The researchers hypothesized that metadata is usually found on the first page of PDFs and varies by document. They began with Conditional Random Fields to identify and extract relevant data:
- They analyzed font changes to help identify metadata.
- They used BiLSTM with BERT embeddings for enhanced extraction capabilities.
- They explored Grobid, a library designed for parsing document sections into structured formats.
The results were impressive:
- The CRF model achieved an F1 score of 0.73 for structured data.
- BiLSTM reached an F1 score of 0.9 for complex data like abstracts.
- Grobid outperformed with an F1 score of 0.96 in author extraction.
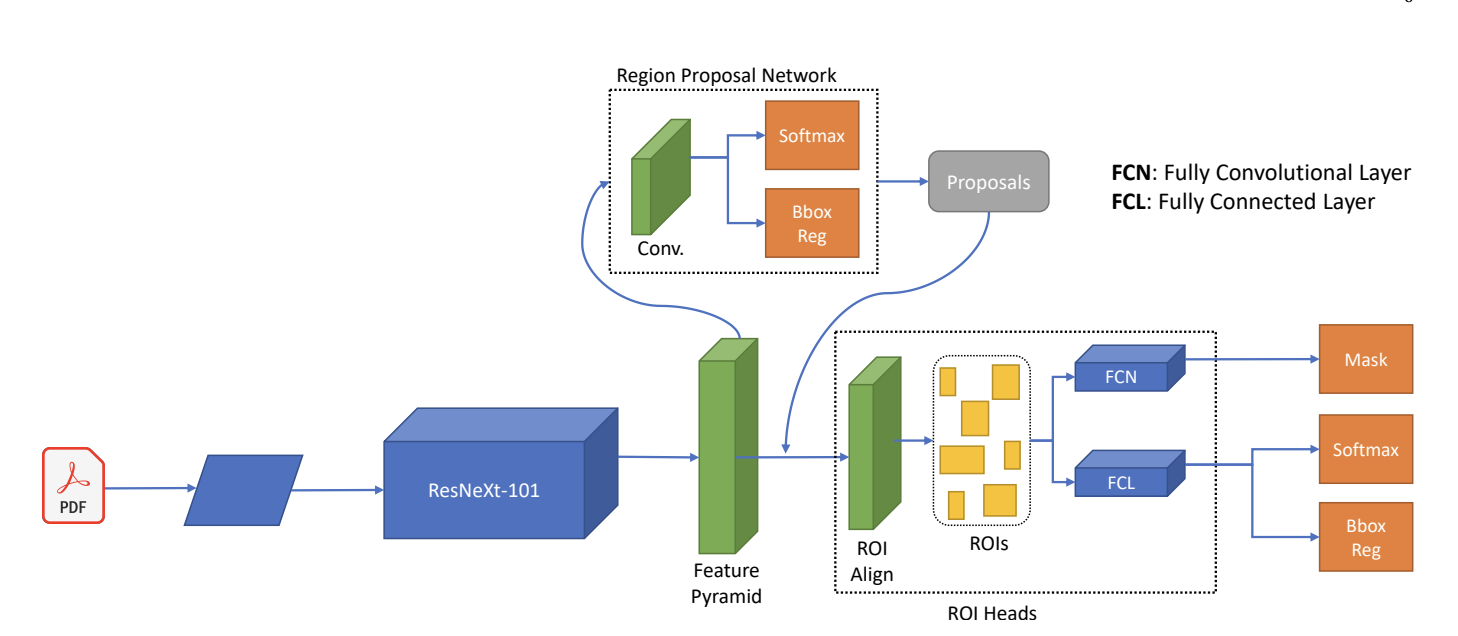
- Fast RCNN showed high accuracy across various metadata types.
- The TextMap method excelled with Word2Vec embeddings, achieving an F1 score of 0.9.
Conclusion
The research compared classical and modern machine-learning tools for metadata extraction, detailing the benefits and limitations of each method. This allows users to choose the best approach based on their specific needs.
For more insights, check out the paper and follow us on Twitter, Telegram, and LinkedIn. Join our growing ML SubReddit community.
Transform Your Company with AI
Stay competitive and leverage AI solutions to enhance your operations:
- Identify Automation Opportunities: Find areas where AI can improve efficiency.
- Define KPIs: Measure AI’s impact on your business outcomes.
- Select an AI Solution: Choose tools that fit your requirements.
- Implement Gradually: Start small, analyze data, and expand AI usage wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing AI insights, follow us on Telegram and Twitter.
Explore how AI can transform your sales and customer engagement at itinai.com.























