
Understanding Diffusion Models and Their Challenges
Diffusion models create images by gradually turning random noise into clear pictures. A big challenge with these models is their high computational cost, especially when dealing with complex pixel data. Researchers are looking for ways to make these models faster and more efficient without losing image quality.
The Problem with Latent Space
One major issue in diffusion models is how the latent space is structured. Traditional methods like Variational Autoencoders (VAEs) help organize this space but often fail to produce high-quality images. While Autoencoders (AEs) can create better images, they can complicate the latent space, making training harder. What’s needed is a tokenizer that balances structure and image quality.
Research Developments
Researchers have tried different methods to improve this situation. VAEs use constraints to create smooth representations, while some align latent structures with existing models for better performance. Yet, these methods still face challenges like high computational costs and scalability issues.
Introducing MAETok
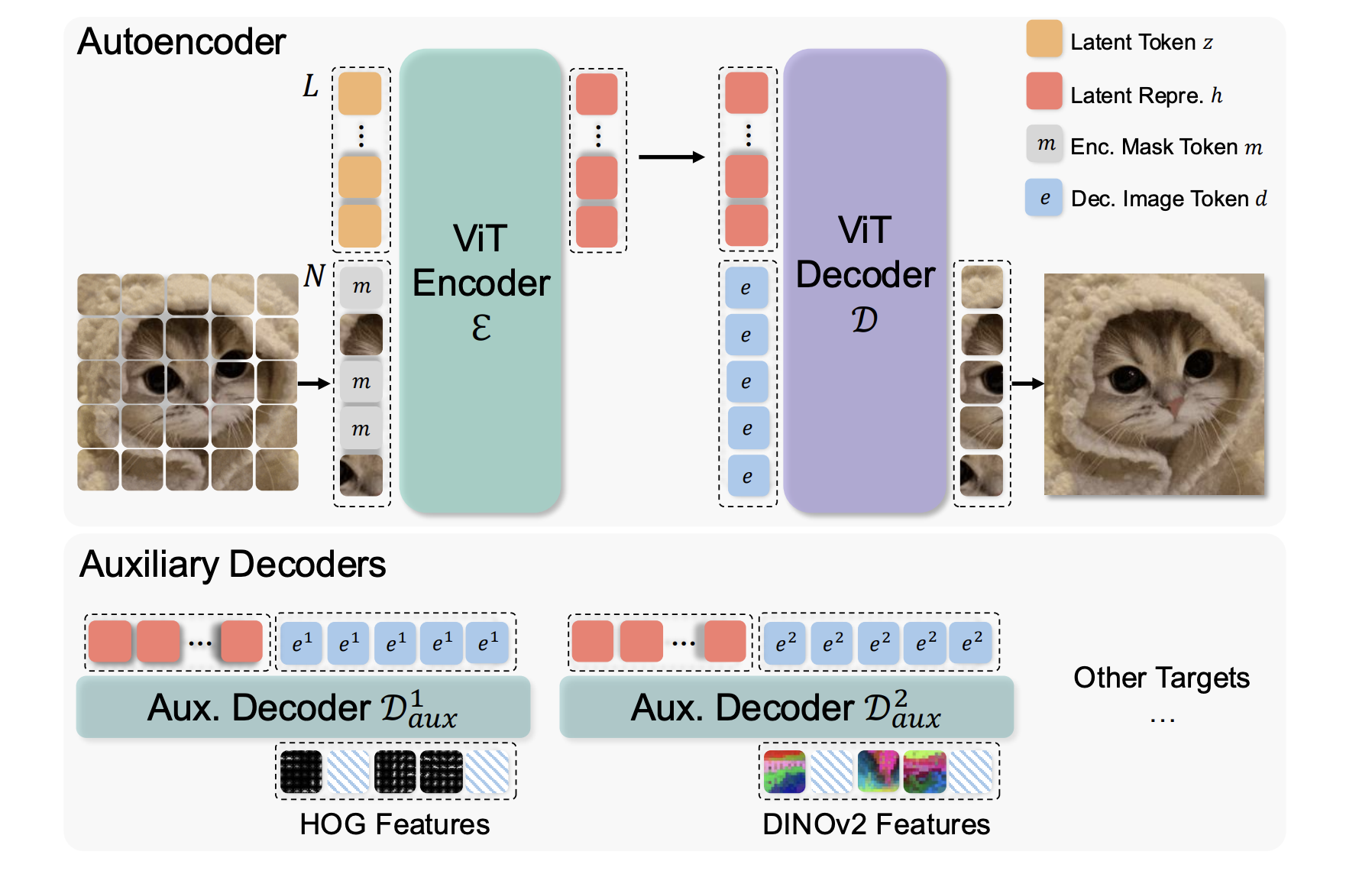
A collaborative research team from Carnegie Mellon University, The University of Hong Kong, Peking University, and AMD has developed a new tokenizer called Masked Autoencoder Tokenizer (MAETok). This innovative approach uses masked modeling in an autoencoder setup, creating a structured latent space that still maintains high image quality.
How MAETok Works
MAETok is based on a Vision Transformer architecture and consists of an encoder and a decoder. The encoder processes images divided into patches, using learnable latent tokens. During training, some tokens are randomly hidden, prompting the model to predict these missing pieces from the visible data. This process helps the model learn rich and useful representations. Additionally, shallow decoders refine the latent space quality, making training easier and faster.
Performance Results
Extensive tests show that MAETok performs exceptionally well, achieving state-of-the-art results on ImageNet with much lower computational needs. It uses only 128 latent tokens and achieves a generative Frechet Inception Distance (gFID) of 1.69 for 512×512 images. Training was 76 times faster, and the model processed data 31 times quicker than traditional methods. This shows that a well-structured latent space can lead to better image generation.
Significance of the Research
This study emphasizes the need for effective latent space structuring in diffusion models. By using masked modeling, researchers found a successful balance between image quality and computational efficiency. These findings pave the way for further improvements in diffusion-based image creation, making it more scalable and efficient without compromising on quality.
Join the AI Community
Explore more about this research by checking out the Paper and GitHub Page. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. Also, become a part of our thriving machine learning community on SubReddit.
Transform Your Business with AI
If you want to enhance your business using AI, consider the following steps:
- Identify Automation Opportunities: Find customer interaction points where AI can help.
- Define KPIs: Make sure your AI initiatives have measurable goals.
- Select an AI Solution: Choose tools that fit your needs and allow for customization.
- Implement Gradually: Start small, gather data, and expand AI use wisely.
For AI KPI management advice, reach out to us at hello@itinai.com. For ongoing insights into AI, follow us on Telegram or @itinaicom.
Discover how AI can transform your sales processes and customer engagement at itinai.com.

























