
Spoken Term Detection (STD) Overview
Spoken Term Detection (STD) helps identify specific phrases in large audio collections. It’s used in voice searches, transcription services, and multimedia indexing, making audio data easier to access and use. This is particularly valuable for podcasts, lectures, and broadcast media.
Challenges in Spoken Term Detection
One major challenge is managing out-of-vocabulary (OOV) terms and the heavy computing required by traditional systems. Current methods often rely on automatic speech recognition (ASR), which can be inaccurate and resource-intensive, especially with shorter audio clips or varying sound conditions. They struggle to accurately segment continuous speech, which hampers term identification.
Current Approaches to STD
Current techniques include ASR-based methods, dynamic time warping (DTW), and acoustic word embeddings. However, these methods face issues such as speaker variability, inefficiency, and limitations in adapting to different datasets, especially for unknown terms.
Introducing BEST-STD
A team from the Indian Institute of Technology Kanpur and imec – Ghent University has created a new framework called BEST-STD. This innovative approach converts speech into speaker-neutral semantic tokens, making it easier to retrieve spoken content using text-based algorithms.
How BEST-STD Works
The BEST-STD system uses a bidirectional Mamba encoder that processes audio from both directions, capturing long-range dependencies. It converts audio data into token sequences via a vector quantizer, employing self-supervised learning to ensure consistency in token representations regardless of the speaker.
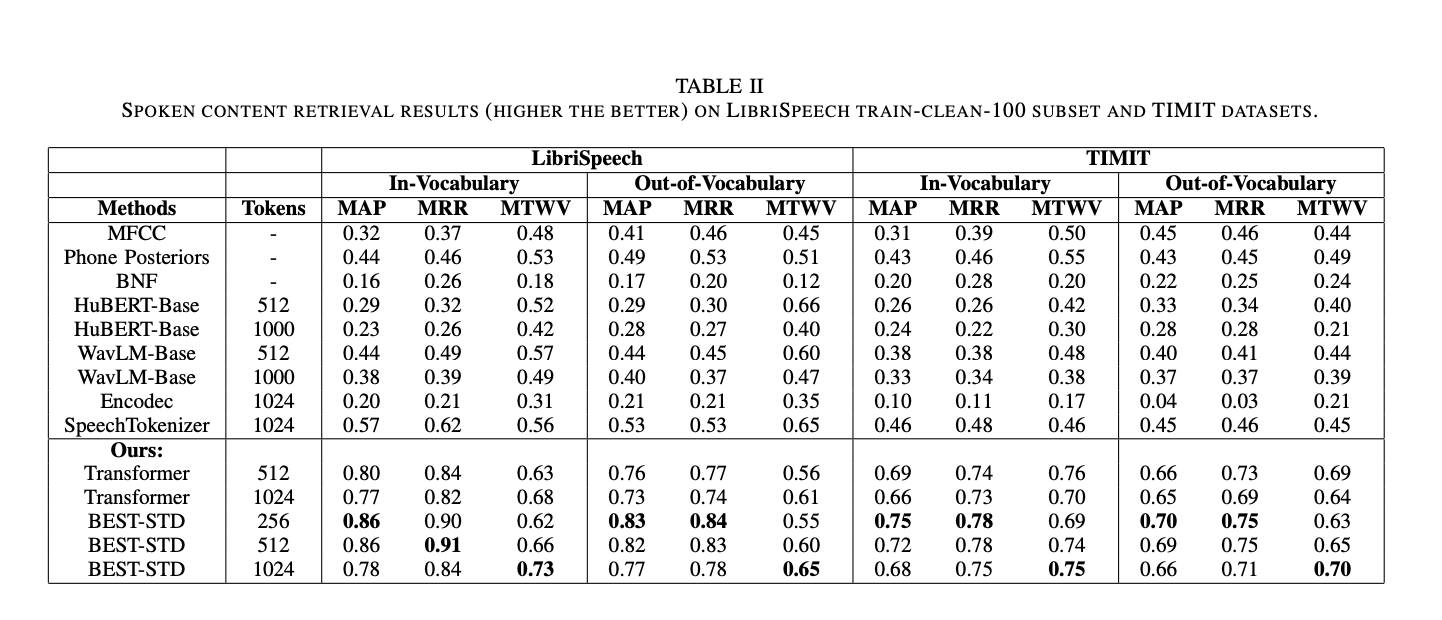
Performance Benefits of BEST-STD
BEST-STD has shown impressive results in tests, scoring higher in token consistency compared to traditional methods and other tokenization models. For spoken content retrieval, it achieved high mean average precision (MAP) and mean reciprocal rank (MRR) scores, demonstrating its effectiveness with both in-vocabulary and out-of-vocabulary terms.
Advantages of the Framework
BEST-STD stands out for its fast retrieval speeds and efficiency, utilizing an inverted index for tokenized sequences. It reduces the need for heavy computational matching techniques, making it viable for large datasets. The bidirectional encoder also outperforms traditional methods due to its ability to handle fine-grained temporal information.
Conclusion
The BEST-STD framework is a significant improvement in spoken term detection, offering a robust solution for audio retrieval tasks. Its speaker-neutral tokens and advanced encoding technique enhance performance and adaptability, promising better accessibility and searchability in audio processing.
Learn More
Check out the Paper for more insights, and stay connected with us on Twitter, join our Telegram Channel, and be part of our LinkedIn Group. Don’t forget to subscribe to our newsletter and join our 55k+ ML SubReddit.
Stay Competitive with AI
Explore how AI can transform your business. Identify Automation Opportunities, Define KPIs, Select AI Solutions, and Implement Gradually. For consultation, contact us at hello@itinai.com and follow us for ongoing AI insights.

























