
Practical Solutions for Memory Efficiency in Large Language Models
Understanding the Challenge
Large language models (LLMs) excel at complex language tasks but face memory issues due to storing contextual information.
Efficient Memory Management
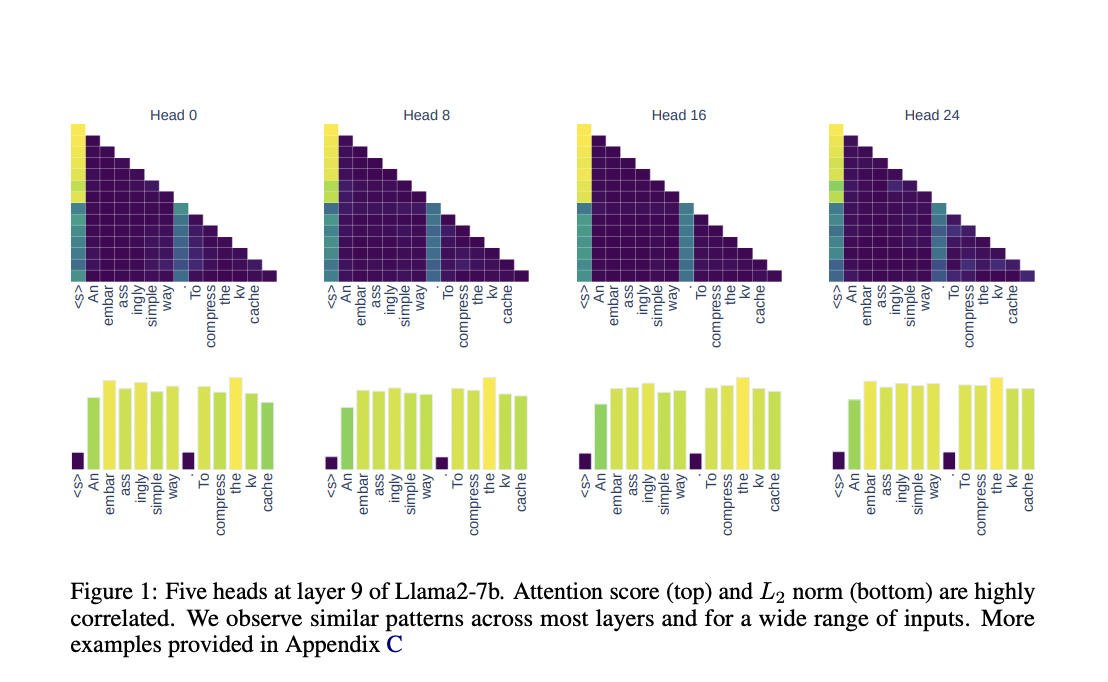
Reduce memory usage by compressing key-value pairs with a novel L2 norm-based strategy.
Value Proposition
Significantly lower memory footprint while maintaining high accuracy in various tasks.
Key Benefits
- Up to 50% memory reduction in language modeling tasks with no impact on accuracy.
- 100% accuracy in tasks like passkey retrieval even with 90% cache compression.
- 99% accuracy in challenging tasks like needle-in-a-haystack with 50% cache compression.
Practical Implementation
Simple, non-intrusive method applicable to any transformer-based LLM without extensive retraining.
Future Applications
Enables broader adoption of LLMs across industries with evolving complexity in tasks.

























