
Understanding Dense Embedding-Based Text Retrieval
Dense embedding-based text retrieval is essential for ranking text passages based on user queries. It uses deep learning models to convert text into vectors, allowing for the measurement of semantic similarity. This approach is widely used in search engines and retrieval-augmented generation (RAG), where accurate and relevant information retrieval is crucial.
Challenges in the System
One major challenge is that these systems can be manipulated by malicious actors. Since they rely on public data, adversaries can insert misleading content, skewing search results and spreading misinformation. This compromises the reliability of knowledge systems.
Previous Defense Methods
Past attempts to combat these attacks involved basic techniques, like flooding queries with repetitive text. However, these methods often fail against complex models and do not address the core vulnerabilities of embedding-based systems.
Introducing GASLITE
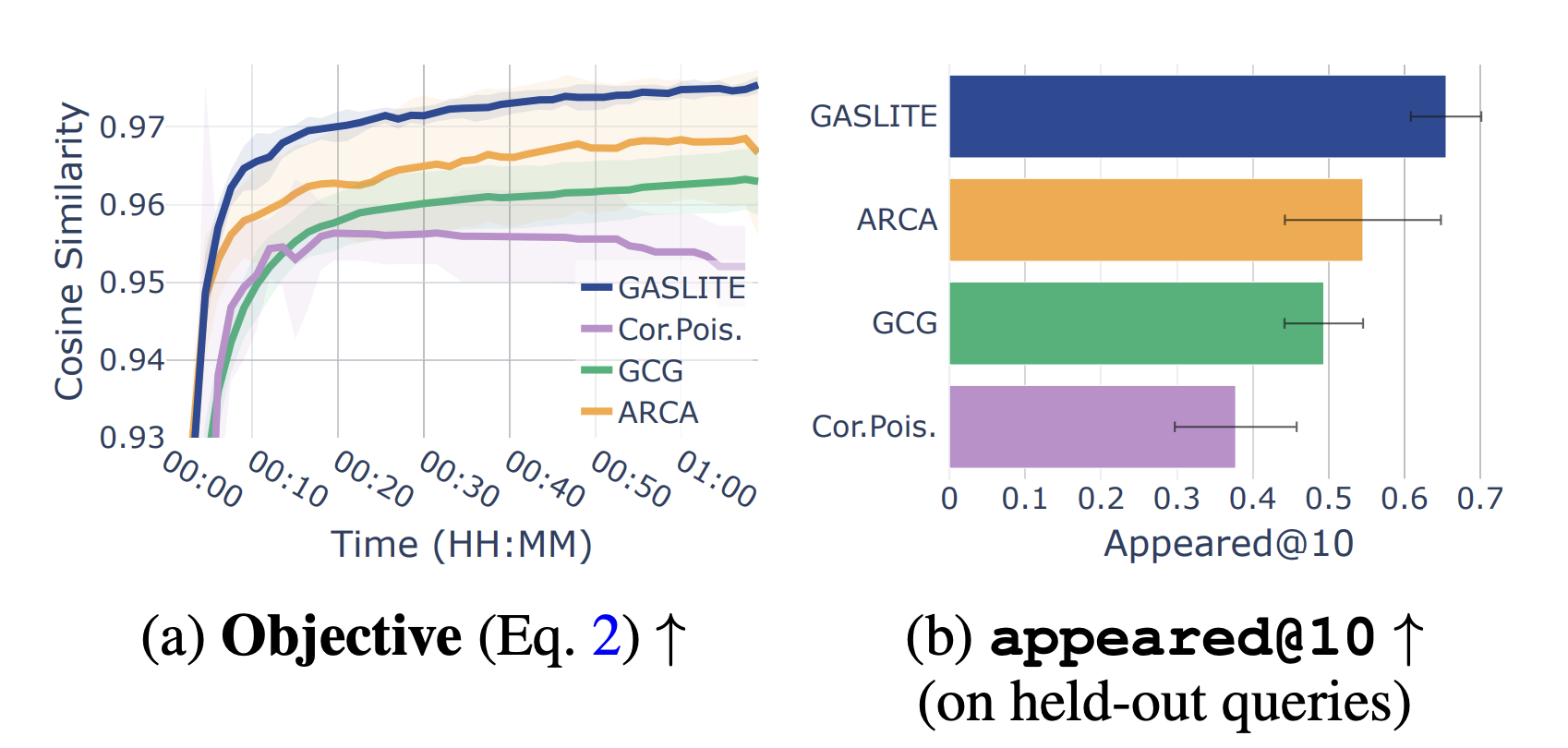
Researchers at Tel Aviv University developed a new method called GASLITE, which uses a mathematical approach to create adversarial passages. This method is more effective because it targets the embedding space of the retrieval model rather than altering the text itself.
How GASLITE Works
GASLITE constructs adversarial passages using specific prefixes and optimized triggers to align with targeted query distributions. It employs gradient calculations to find the best token substitutions, making it stealthy and effective. Adversarial passages can blend into the existing corpus without detection.
Performance Results
In tests with nine advanced retrieval models, GASLITE achieved a success rate of 61-100% in ranking adversarial passages among the top 10 results for specific queries, using only a tiny fraction of the dataset for adversarial content. This demonstrates its precision and efficiency.
Understanding Vulnerabilities
The success of GASLITE highlights the importance of understanding the geometry of embedding spaces and similarity metrics. Models that use dot-product similarity are particularly vulnerable, and those with anisotropic embedding spaces are at higher risk of attacks.
Recommendations for Defense
To protect against these manipulations, researchers recommend using hybrid retrieval approaches that combine dense and sparse techniques. This can help mitigate risks posed by methods like GASLITE and enhance the security of retrieval systems.
Call to Action
It is crucial to address the risks posed by adversarial attacks on dense embedding-based systems. The ease with which GASLITE can manipulate search results underscores the potential severity of these threats. By identifying vulnerabilities and developing effective defenses, we can improve the robustness and reliability of retrieval models.
Learn More
Check out the Paper and GitHub Page for more details. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. Don’t forget to join our 60k+ ML SubReddit.
Join Our Webinar
Gain actionable insights into enhancing LLM model performance while ensuring data privacy.
Transform Your Business with AI
Stay competitive and leverage AI solutions to redefine your operations:
- Identify Automation Opportunities: Find key customer interactions that can benefit from AI.
- Define KPIs: Ensure measurable impacts from your AI initiatives.
- Select an AI Solution: Choose tools that fit your needs and allow for customization.
- Implement Gradually: Start with a pilot project, gather data, and expand AI usage wisely.
For AI KPI management advice, connect with us at hello@itinai.com. For ongoing insights into AI, follow us on Telegram or Twitter.
Enhance Your Sales and Customer Engagement
Discover how AI can transform your sales processes and customer interactions. Explore solutions at itinai.com.
























