
Understanding Long-Context Large Language Models (LLMs)
Long-context LLMs are built to process large amounts of information effectively. With improved computing power, these models can handle various tasks, especially those requiring detailed knowledge through Retrieval Augmented Generation (RAG). Increasing the number of documents retrieved can enhance performance, but simply adding more information isn’t always beneficial. Too much data can introduce noise, leading to decreased performance. Thus, optimizing RAG for long contexts is a complex challenge.
Innovative Solutions for Efficient Context Handling
Earlier methods to extend context lengths included using sparse and low-rank kernels to save memory. Newer approaches involve recurrent models and state space models (SSMs) as efficient alternatives to traditional transformer models. Recent advancements in attention methods allow LLMs to work with input sequences containing millions of tokens. In-context learning (ICL) enhances efficiency by showing examples during processing, and recent improvements in pretraining help models learn better in context.
Enhancing RAG Performance
Retrieval Augmented Generation (RAG) boosts language model performance by sourcing relevant external information. Enhancing the selection process for relevant documents improves answer quality. New methods for managing large documents and scaling storage have been introduced to further improve RAG’s effectiveness.
Research Insights on Inference Scaling
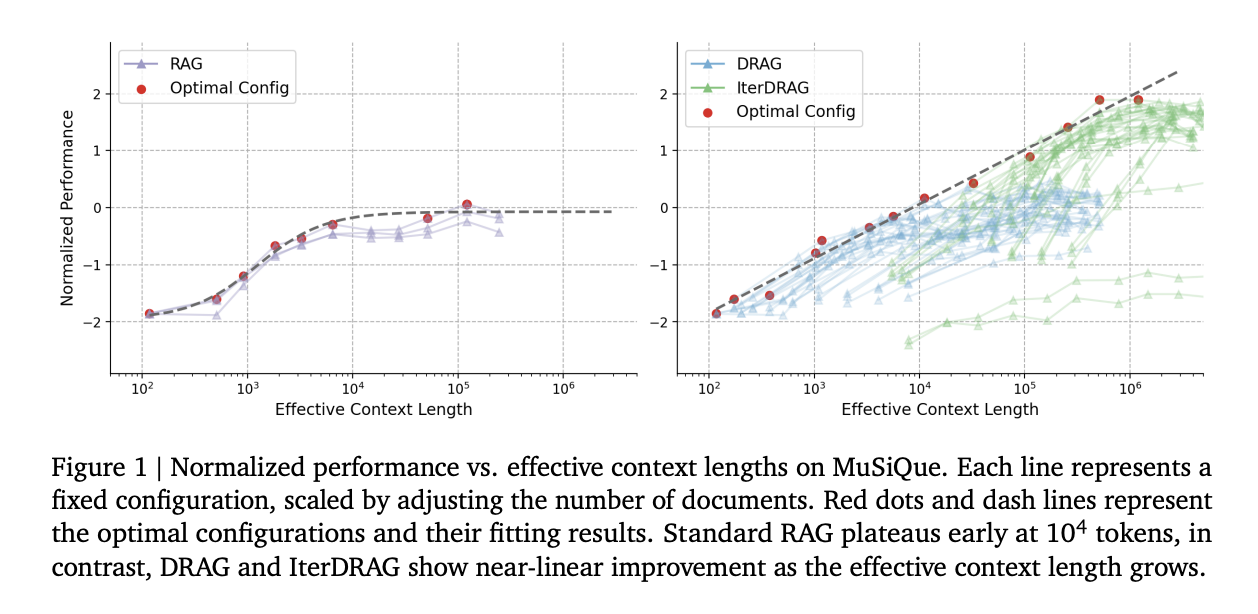
Despite advancements, optimizing inference scaling for long-context RAG in knowledge-heavy tasks is still under-researched. A team from Google DeepMind and several universities studied how different inference strategies affect RAG performance. They focused on in-context learning and iterative prompting, which allow for better use of computational resources during inference.
Key Findings from the Research
The research found that smart allocation of inference computation leads to significant performance improvements in RAG. They developed a computation allocation model to predict optimal performance under various conditions. They introduced Demonstration-based RAG (DRAG), which teaches the model to find relevant information through examples. To tackle more complex tasks, they created Iterative DRAG (IterDRAG), which breaks down queries into smaller parts for more effective retrieval and reasoning.
Performance Evaluation
Comparing different RAG strategies revealed that DRAG and IterDRAG outperform traditional methods, especially with longer context lengths. DRAG excels with shorter contexts, while IterDRAG benefits from iterative retrieval, demonstrating improved performance as computing power increases. This iterative approach allows models to manage complex queries effectively.
Conclusion and Future Insights
The introduction of DRAG and IterDRAG enhances the efficiency of RAG, proving more effective than merely increasing document retrieval. The research established inference scaling laws for RAG and a model to predict performance across different configurations. These findings lay a strong foundation for future developments in optimizing inference strategies for long-context RAG.
Get Involved
Check out the full paper for more insights. Follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you appreciate our work, subscribe to our newsletter and join our thriving 50k+ ML SubReddit.
Upcoming Webinar
Upcoming Live Webinar- Oct 29, 2024: Discover the best platform for serving fine-tuned models with the Predibase Inference Engine.
Transform Your Business with AI
Stay competitive by leveraging AI solutions. Here are some practical steps:
- Identify Automation Opportunities: Find key customer interaction points for AI benefits.
- Define KPIs: Ensure measurable impacts from your AI initiatives.
- Select an AI Solution: Choose tools that meet your specific needs and allow customization.
- Implement Gradually: Start with a pilot program, gather data, and expand wisely.
For AI KPI management advice, connect with us at hello@itinai.com. For ongoing insights, follow us on Telegram or Twitter.
Explore how AI can enhance your sales processes and customer engagement at itinai.com.

























