
Practical Solutions for Efficient Large Language Model Inference
Addressing Efficiency Challenges in Large Language Models
Large Language Models (LLMs) are AI systems that understand and generate human language. However, they face challenges in processing long texts efficiently due to the quadratic time complexity of the Transformer architecture they use.
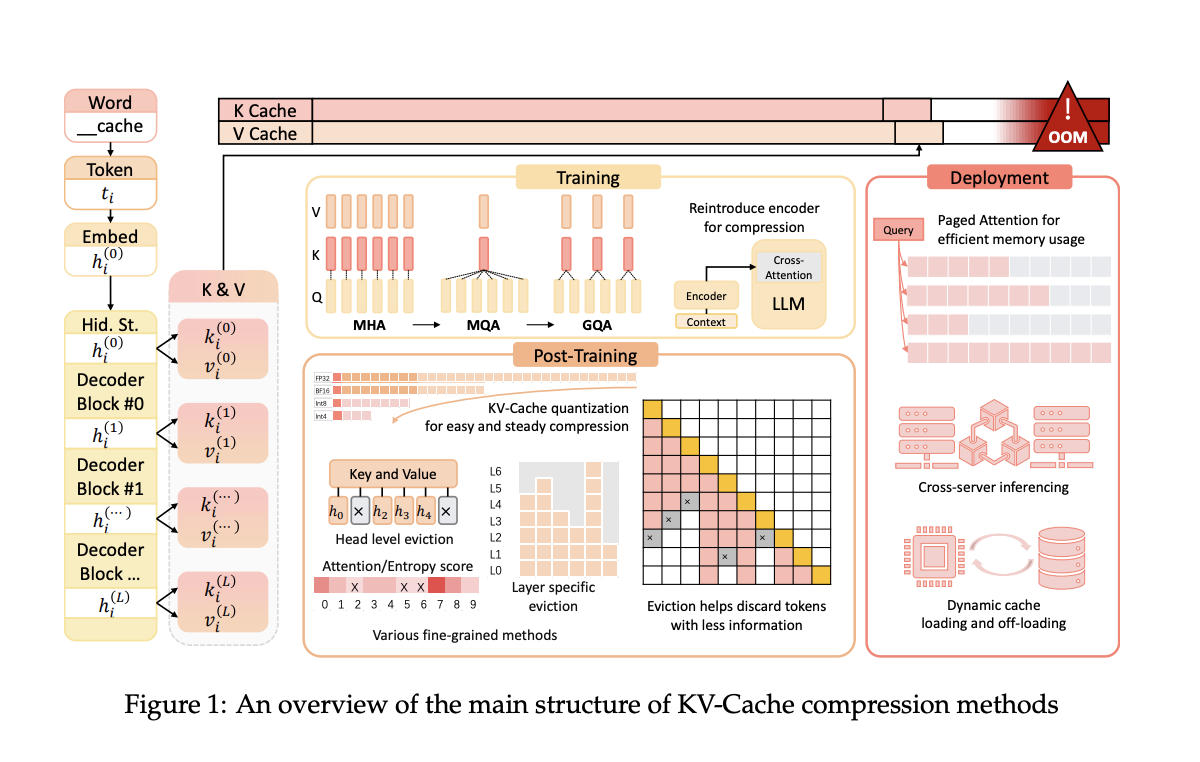
Researchers have introduced the KV-Cache mechanism to reduce time complexity from quadratic to linear, but this increases GPU memory usage, creating a new bottleneck.
Optimizing KV-Cache for Enhanced Efficiency
Researchers from Wuhan University and Shanghai Jiao Tong University have introduced methods to optimize KV-Cache space usage across LLMs’ pre-training, deployment, and inference phases. These methods aim to reduce memory requirements without compromising performance.
The proposed methods include architectural adjustments during pre-training, deployment frameworks like Paged Attention and DistKV-LLM, and post-training methods such as dynamic eviction strategies and quantization techniques.
Significant Improvements in Memory Efficiency and Inference Speed
The introduced methods have shown significant improvements in memory efficiency and inference speed, achieving better memory utilization and reduced latency. For instance, the GQA method used in popular models like LLaMA2-70B achieves a 75% reduction in KV-Cache size while maintaining performance levels.
Advancing AI Solutions with Efficient Memory Management
Implementing these methods can lead to higher efficiency and better performance of LLMs, paving the way for more sustainable and scalable AI solutions. The research provides comprehensive strategies for optimizing KV-Cache in LLMs, offering a roadmap for future advancements in LLM technology.
If you want to evolve your company with AI, stay competitive, and use AI for your advantage, consider implementing these KV-Cache optimization techniques for efficient Large Language Model Inference.
AI Solutions for Business Transformation
Discover how AI can redefine your way of work by identifying automation opportunities, defining KPIs, selecting an AI solution, and implementing gradually. For AI KPI management advice and continuous insights into leveraging AI, connect with us at hello@itinai.com and stay tuned on our Telegram or Twitter.
Explore how AI can redefine your sales processes and customer engagement by visiting itinai.com.
























