
Understanding Language Model Efficiency
Training and deploying language models can be very costly. To tackle this, researchers are using a method called model distillation. This approach trains a smaller model, known as the student model, to perform like a larger one, called the teacher model. The goal is to use fewer resources while keeping high performance.
Challenges of Large Models
The rapid growth of machine learning models has led to significant expenses and sustainability issues. They require a lot of computational power for both training and making predictions, which can be more expensive than the initial training process. Here are some challenges:
- High energy consumption
- Logistical difficulties in deployment
- Need for reduced inference costs without losing capabilities
Previous Solutions and Their Limitations
Past techniques to handle large model training include:
- Compute-optimal training: Finds the best model size and data within a budget.
- Overtraining: Uses more data than optimal for better model effectiveness.
However, these methods can lead to longer training times and less improvement in performance. While compression and pruning have been tried, they often reduce effectiveness. Therefore, a structured method like distillation is essential for improving efficiency.
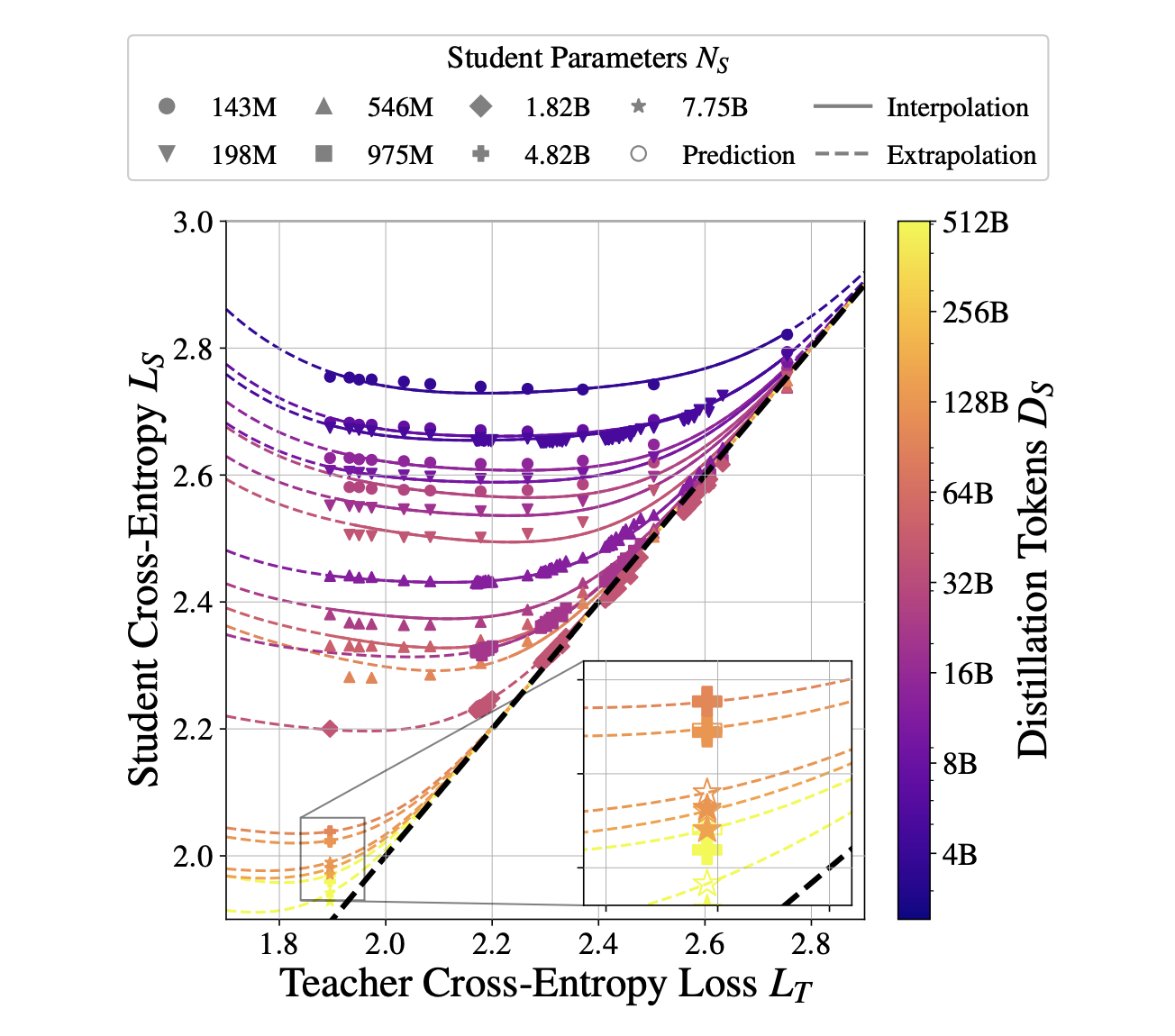
Introducing the Distillation Scaling Law
Researchers from Apple and the University of Oxford have developed a distillation scaling law. This framework helps in:
- Strategically allocating computational resources between teacher and student models.
- Providing guidelines for optimal distillation.
- Clarifying when distillation is better than traditional supervised learning.
It shows how the performance of the student model depends on the teacher model’s effectiveness, dataset size, and training parameters.
Key Findings from the Research
The research highlighted the following:
- A student’s learning ability is influenced by the teacher’s performance.
- Stronger teachers don’t always lead to better student models due to differences in learning capacity.
- When resources are properly allocated, distillation can be as effective or more efficient than traditional methods.
Practical Applications and Benefits
The findings from this research offer practical insights for enhancing model efficiency. They help reduce inference costs while keeping strong performance, making AI models more suitable for real-world use. This means companies can develop smaller yet powerful models that achieve high performance with lower computational costs.
How AI Can Transform Your Business
To stay competitive, consider the following steps to integrate AI:
- Identify Automation Opportunities: Find areas in customer interactions that can benefit from AI.
- Define KPIs: Ensure your AI initiatives have measurable impacts on your business.
- Select an AI Solution: Choose tools that fit your needs and allow for customization.
- Implement Gradually: Start with a pilot project, gather data, and expand AI use wisely.
For AI KPI management advice, contact us at hello@itinai.com. For continuous AI insights, follow us on Telegram or Twitter @itinaicom.
Discover how AI can enhance your sales and customer engagement by exploring solutions at itinai.com.
























