
Advancements in Large Language Models (LLMs)
Emerging Capabilities of LLMs
Scaling LLMs and their training data has led to impressive abilities in structured reasoning, logical deductions, and abstract thinking. These advancements bring us closer to achieving Artificial General Intelligence (AGI).
The Challenge of Reasoning in LLMs
Training LLMs to reason effectively is a significant challenge. Current methods struggle with multi-step problems that require logical coherence. The dependence on human-annotated training data limits these models’ abilities, making it hard to apply them to complex real-world issues.
Partial Solutions Existing Today
Researchers have attempted solutions such as supervised fine-tuning and reinforcement learning from human feedback (RLHF). While these have improved LLM performance, they still rely heavily on high-quality datasets and vast computational resources, which are not scalable.
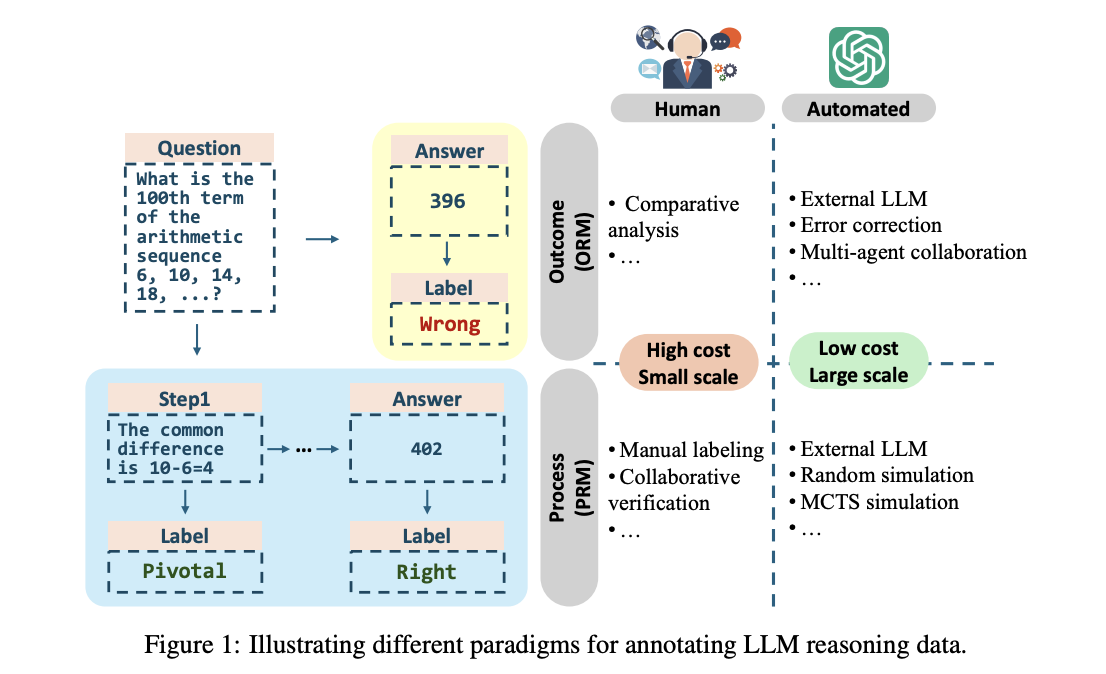
An Innovative Approach from Researchers
Researchers from Tsinghua University, Emory University, and HKUST have developed a new reinforced learning method to enhance LLM reasoning. This approach uses Process Reward Models (PRMs) that guide intermediate reasoning steps, improving logical coherence and overall performance.
Automated Reasoning Data Generation
By combining automated annotation with Monte Carlo simulations, the researchers generated high-quality reasoning data without manual help. This method allows models to learn advanced reasoning through iterative processes, reducing the need for human intervention.
Step-Level Guidance for LLMs
PRMs provide rewards based on intermediate steps instead of just final outcomes. This detailed guidance helps models learn incrementally. Additionally, test-time scaling gives more computational resources for intensive reasoning during inference, enhancing overall capabilities.
Significant Performance Improvements
Models trained with this reinforced learning technique show substantial gains in reasoning tasks. For instance, the OpenAI o1 series achieved an 83.3% success rate in programming and performed at a gold medal level in International Mathematics Olympiad. Accuracy has improved by 150% compared to earlier models.
The Future of LLMs with Advanced Learning
This research highlights the potential of LLMs when paired with innovative reinforcement learning strategies. It paves the way for creating AI systems capable of tackling complex tasks with minimal human input.
Transform Your Business with AI
Embracing AI can revolutionize your company. Here’s how to get started:
– **Identify Automation Opportunities**: Find key areas in customer interactions that can benefit from AI.
– **Define KPIs**: Ensure measurable impacts from your AI initiatives.
– **Select an AI Solution**: Choose tools that meet your needs and offer flexibility.
– **Implement Gradually**: Begin with a pilot project, collect data, and expand thoughtfully.
For expert advice on AI KPI management, reach out to us at hello@itinai.com. For ongoing insights, stay connected on our Telegram channel t.me/itinainews or Twitter @itinaicom.
Explore Further
Check out the full research paper for more insights. Follow us on Twitter, join our Telegram Channel, and become part of our LinkedIn Group. Don’t forget to explore over 65k+ members in our ML SubReddit!


























