
Synthetic Data Generation for Advanced AI Training
Synthetic data generation is crucial for training large language models (LLMs). It involves creating artificial data sets that mimic real-world data to effectively train and evaluate machine learning models without compromising privacy or extensive data collection efforts. The challenge lies in creating diverse and scalable data sets to enhance the robustness and performance of LLMs in various applications.
Traditional Challenges in Synthetic Data Generation
Traditional methods struggle to maintain both diversity and scalability:
- Instance-driven approaches are limited by the diversity of the original data set.
- Key-point-driven methods are difficult to scale across different domains due to exhaustive curation required.
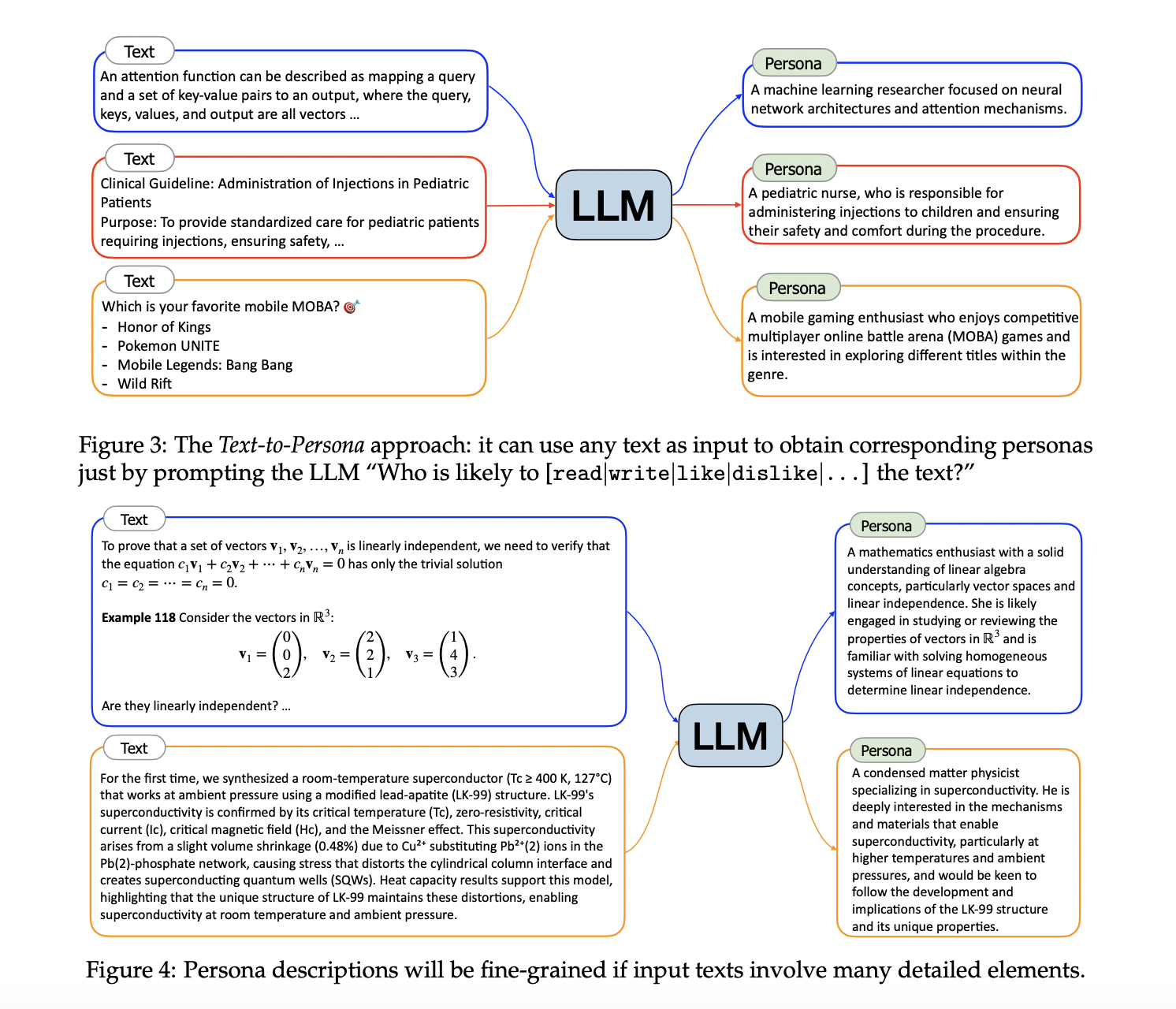
Persona Hub: Innovative Persona-Driven Approach
Persona Hub, introduced by Tencent AI Lab, leverages a collection of one billion diverse personas to generate synthetic data. This method allows LLMs to create data from various perspectives, enhancing diversity and scalability. Persona Hub provides impressive quantitative results and promises to become a standard practice in synthetic data generation.
Impact and Future Potential
The persona-driven methodology addresses the limitations of traditional methods and promises to enhance the capabilities of LLMs. This innovative method can drive significant advancements in artificial intelligence and machine learning.
Evolve Your Company with AI
If you want to evolve your company with AI and stay competitive, utilize innovative AI solutions to redefine your way of work. Connect with us for AI KPI management advice and continuous insights into leveraging AI.



























