
Practical Solutions and Value of NVLM 1.0: Multimodal Large Language Models
Enhancing Multimodal AI Capabilities
Multimodal large language models (MLLMs) improve AI systems’ ability to understand both text and visual data seamlessly.
Addressing Performance Challenges
NVLM 1.0 models balance text and image processing efficiently, overcoming the trade-offs seen in previous approaches.
Revolutionizing AI Applications
These models excel in tasks like image captioning, document understanding, and interactive AI systems, setting new standards in AI performance.
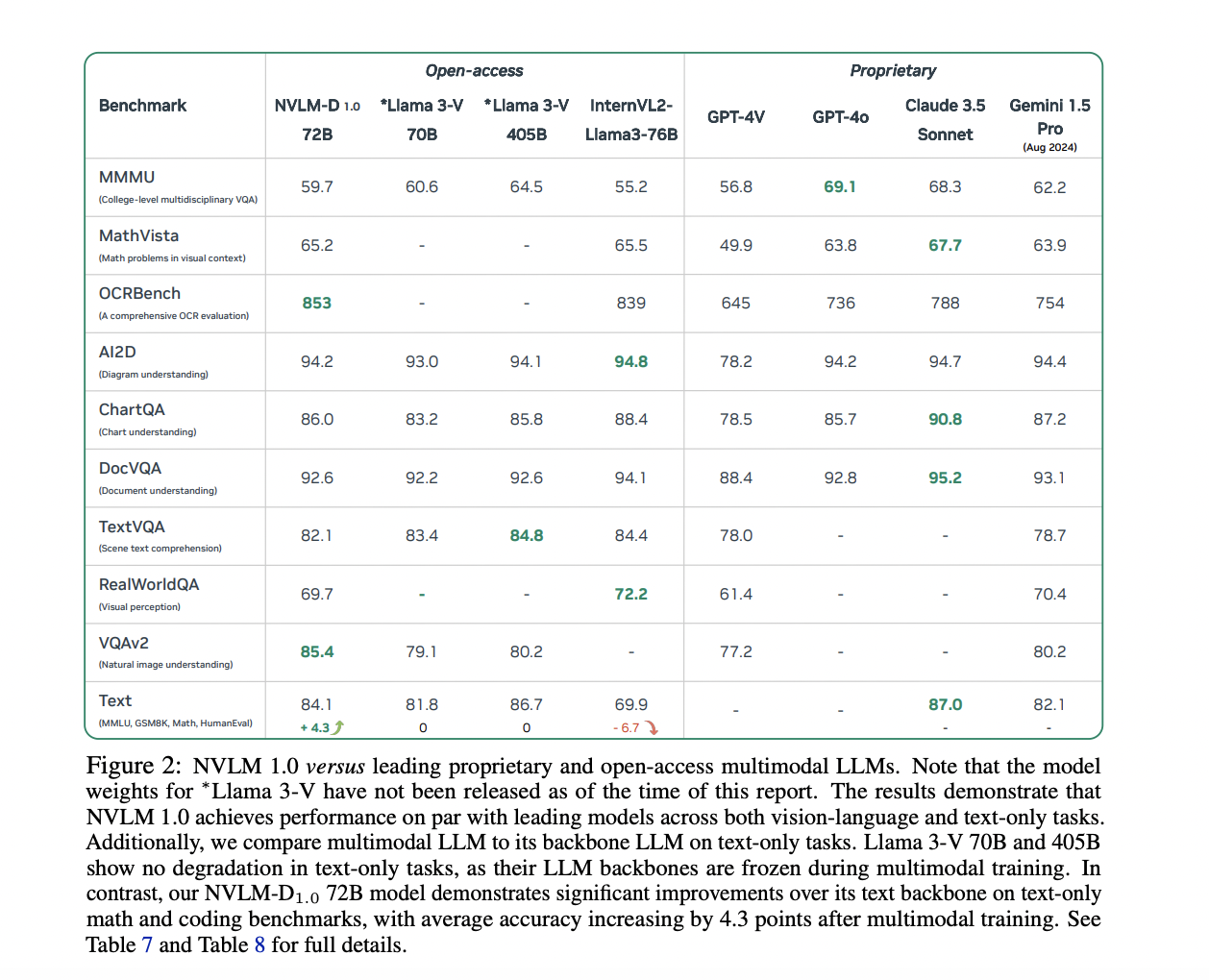
Improving Vision-Language Tasks
NVLM 1.0 models maintain or enhance text-only performance while excelling in vision-language tasks, ensuring robust comprehension across modalities.
Advanced Architectural Designs
By integrating high-quality text datasets and innovative architectural designs like dynamic tiling, NVLM models achieve superior performance in handling complex visual information.
Performance Benchmarks
NVLM 1.0 models demonstrate impressive results across various benchmarks, showcasing their capabilities in text-based reasoning, vision-language tasks, and OCR-related challenges.
AI Evolution with NVLM 1.0
By leveraging NVLM 1.0 models, companies can evolve with AI, stay competitive, and redefine their work processes with enhanced text and image processing capabilities.
AI Implementation Guidance
For successful AI integration, identify automation opportunities, define KPIs, select suitable AI solutions, and implement gradually to optimize business outcomes.
Connect with Us
For AI KPI management advice and continuous insights on leveraging AI, reach out to us at hello@itinai.com or follow us on Telegram and Twitter.
























