
Understanding Large Language Models (LLMs)
Large Language Models (LLMs) are advanced tools that can understand and respond to user instructions. They use a method called transformer architecture to predict the next word in a sentence, allowing them to generate fluent responses. However, these models often lack the ability to think critically before answering, which can lead to inaccuracies, especially in complex tasks.
Challenges with LLMs
One major challenge is that LLMs sometimes fail to consider the complexity of user instructions. While they can handle simple tasks quickly, they struggle with intricate problems that require logical reasoning. Training these models to pause, think, and evaluate their thoughts before responding is resource-intensive and often requires large datasets of human-annotated thoughts, which are not always available.
Innovative Solutions: Thought Preference Optimization (TPO)
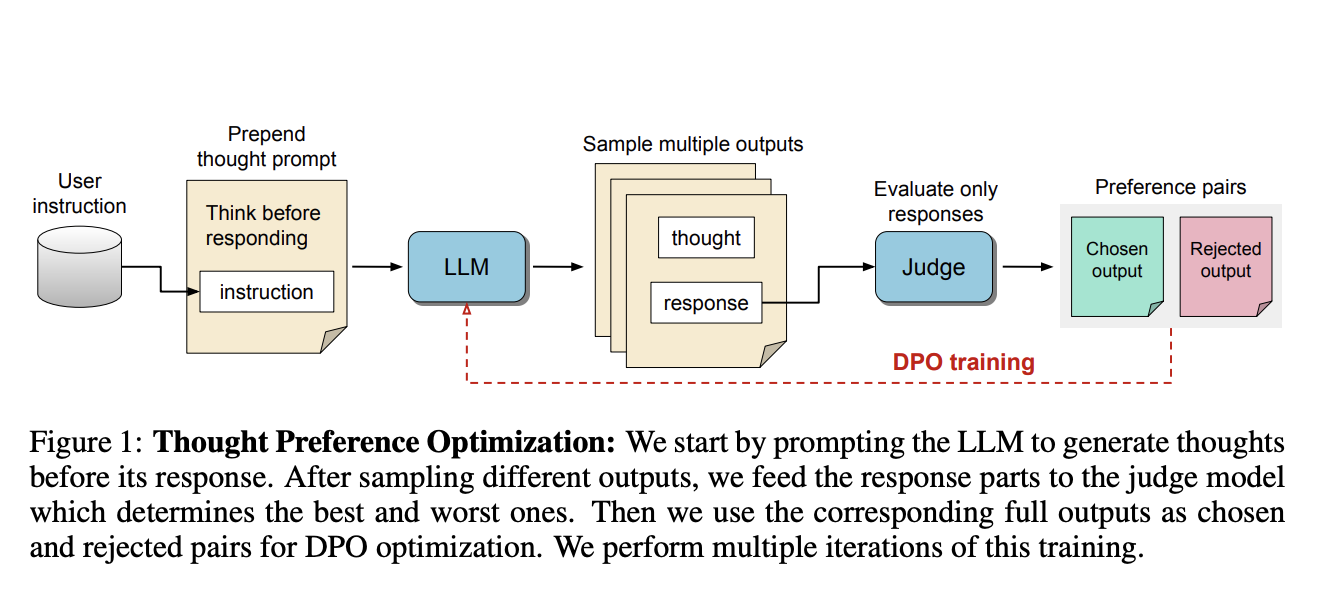
Researchers have introduced a new method called Thought Preference Optimization (TPO). This approach helps LLMs generate and refine their internal thoughts before providing a response. Unlike traditional methods, TPO does not require additional human annotation, making it a cost-effective solution.
How TPO Works
TPO instructs the model to separate its output into two parts: the thought process and the final response. It generates multiple thoughts for each instruction, which are then evaluated to select the best ones for further training. This method uses reinforcement learning to improve the model’s ability to understand complex queries and deliver thoughtful answers.
Proven Effectiveness
TPO has shown significant improvements in performance across various benchmarks. For example, on AlpacaEval, TPO achieved a win rate of 52.5%, surpassing traditional methods. It also performed well in creative writing and marketing tasks, demonstrating its broad applicability.
Key Benefits of TPO
- Increased Win Rates: Achieved a 52.5% win rate on AlpacaEval and 37.3% on Arena-Hard.
- No Need for Human Data: Eliminates reliance on human-labeled data, making it scalable and cost-effective.
- Improved Performance: Enhances results in non-reasoning tasks like marketing and creative writing.
- Self-Improving: The model continues to refine its reasoning with each training iteration.
- Broad Applicability: Effective in various domains beyond traditional reasoning tasks.
Conclusion
Thought Preference Optimization (TPO) significantly improves the ability of LLMs to think before responding, addressing their limitations in handling complex tasks. This innovative approach enhances performance in logic-based problems and creative inquiries alike, making it a promising direction for future developments in AI.
Stay Connected
For more insights, check out the research paper and follow us on Twitter, Telegram, and LinkedIn. If you find our work valuable, consider subscribing to our newsletter or joining our ML SubReddit community.
Transform Your Business with AI
Explore how AI can redefine your operations and improve customer engagement. Identify automation opportunities, define measurable KPIs, select suitable AI solutions, and implement them gradually. For AI KPI management advice, contact us at hello@itinai.com.

























