
Understanding Attention Sinks in Large Language Models
Large Language Models (LLMs) exhibit a unique behavior known as “attention sinks,” where the first token in a sequence, often referred to as the beginning-of-sequence (⟨bos⟩) token, attracts disproportionate attention. This phenomenon has significant implications for the stability and performance of these models. Recent research has highlighted the functional role of attention sinks in maintaining the integrity of token representations, which can ultimately enhance business applications of AI.
The Role of Attention Sinks
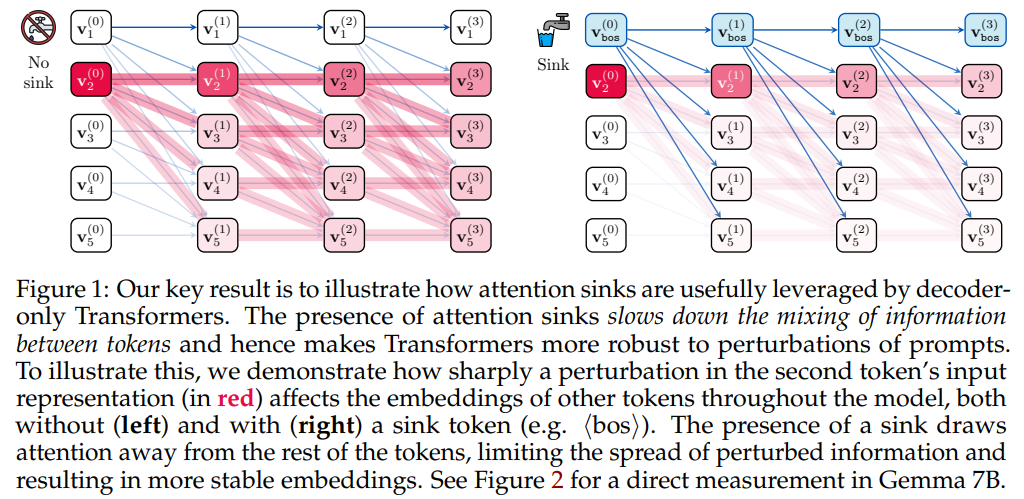
Attention sinks help prevent issues such as over-mixing of token representations, which can lead to instability in deep Transformer models. Researchers from the University of Oxford, NUS, and Google DeepMind found that attention sinks are essential for reducing sensitivity to input noise and preserving distinct token representations over long sequences. This stability is crucial for applications that rely on accurate natural language understanding and generation.
Case Studies and Evidence
Experiments conducted on various models, including Gemma 7B and LLaMa 3.1 405B, demonstrated that attention sinks become more pronounced in deeper models and longer contexts. For instance, removing the ⟨bos⟩ token during inference resulted in a collapse of attention sinks and a significant drop in model performance. This indicates that maintaining the first token’s focus is vital for achieving optimal functionality in LLMs.
Key Findings
- Attention sinks stabilize models by limiting the spread of perturbations.
- They prevent over-squashing, which degrades model performance by compressing diverse inputs.
- Training configurations that consistently include the ⟨bos⟩ token enhance the model’s reliance on attention sinks.
Practical Business Solutions
To leverage insights from the study on attention sinks, businesses can adopt several practical strategies:
- Identify Automation Opportunities: Look for repetitive tasks in customer interactions where AI can add value, such as chatbots for customer service.
- Define Key Performance Indicators (KPIs): Establish metrics to evaluate the effectiveness of your AI investments, ensuring they contribute positively to business outcomes.
- Select Customizable Tools: Choose AI solutions that can be tailored to fit your specific business needs and objectives.
- Start Small: Initiate a pilot project to gather data on AI effectiveness before scaling up your AI initiatives.
Conclusion
In summary, attention sinks play a critical role in stabilizing large language models by focusing attention on the initial token, limiting information mixing, and enhancing model performance. By understanding and applying these principles, businesses can optimize their use of AI technologies, resulting in improved efficiency and effectiveness in language processing tasks. Embracing these insights will not only enhance AI capabilities but also drive significant value across various business operations.


























