
Practical Solutions for Efficient Language Models
Challenges in Language Models
Large Language Models (LLMs) face challenges in handling very long sequences due to their quadratic complexity relative to sequence length and substantial key-value (KV) cache requirements. This impacts efficiency during inference, hindering the development of applications that require reasoning over multiple long documents, processing large codebases, or modeling complex environments.
Efficient Architectures and Techniques
Researchers have explored various approaches to address the efficiency challenges in LLMs, including attention-free models, distillation techniques, and speculative decoding. These approaches aim to reduce computational demands while maintaining or surpassing the performance of Transformers.
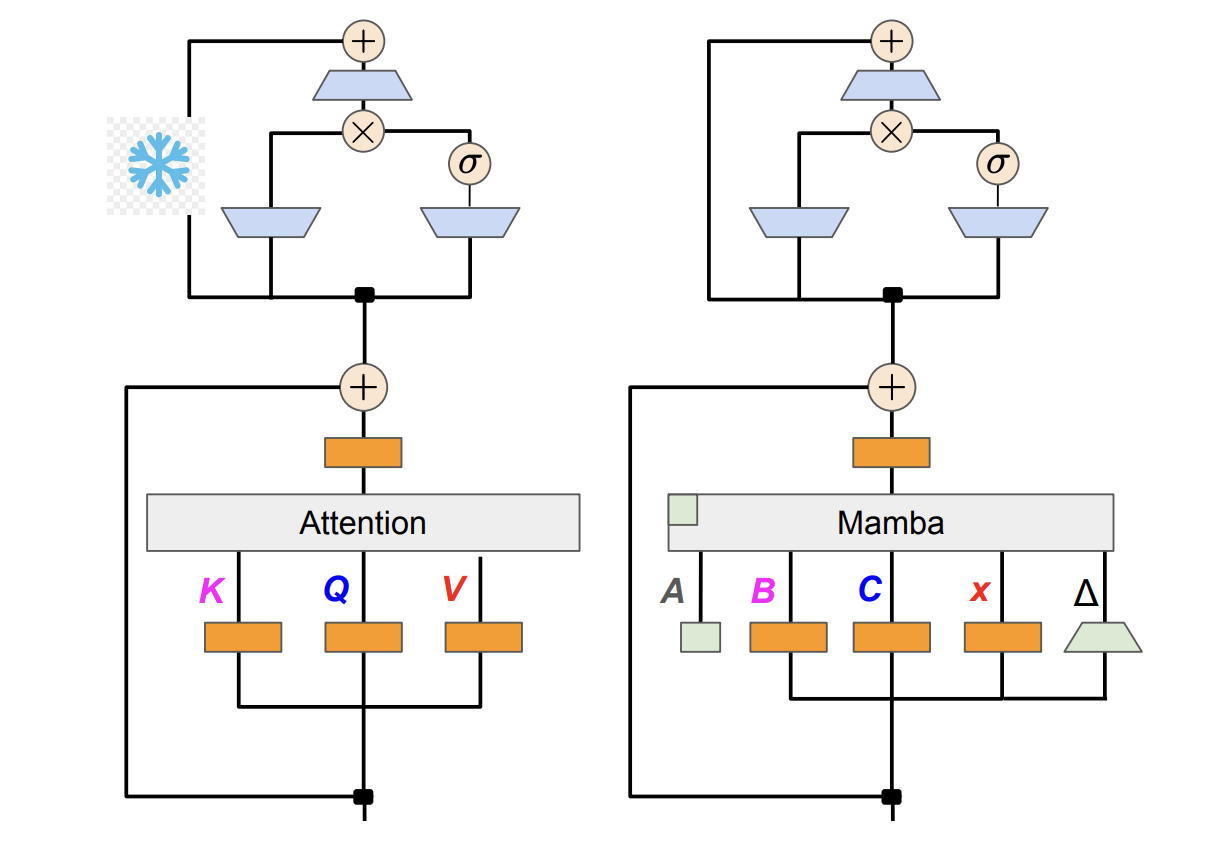
Unique Approach for Efficient LLMs
Researchers propose a unique approach to mitigate the efficiency challenges of LLM models by distilling a pre-trained Transformer into a linear RNN. This method aims to preserve generation quality while significantly improving inference speed. The proposed technique involves mapping Transformer weights to a modified Mamba architecture, introducing a multistage distillation pipeline, and developing a hardware-aware speculative sampling algorithm for efficient inference.
Performance and Efficiency of Hybrid Models
The distilled hybrid Mamba models demonstrate competitive performance on various benchmarks, offering a good balance between efficiency and performance. They achieve comparable or better performance than their teacher models on chat tasks and general language understanding, while also showcasing promising results in speculative decoding experiments.
Value of The Mamba in the Llama: Accelerating Inference with Speculative Decoding
If you want to evolve your company with AI, stay competitive, and leverage efficient language models, consider adopting The Mamba in the Llama: Accelerating Inference with Speculative Decoding. This approach offers a unique method for transforming Transformer models into more efficient Mamba-based models using linear RNNs, demonstrating significant potential for improving the efficiency of LLMs while preserving their capabilities.
AI Solutions for Business Transformation
AI Implementation Guidance
Discover how AI can redefine your way of work by identifying automation opportunities, defining KPIs, selecting AI solutions, and implementing gradually. For AI KPI management advice and continuous insights into leveraging AI, connect with us at hello@itinai.com or stay tuned on our Telegram t.me/itinainews or Twitter @itinaicom.
AI for Sales Processes and Customer Engagement
Explore how AI can redefine your sales processes and customer engagement by discovering solutions at itinai.com.























