
The GTA Benchmark: A New Standard for General Tool Agent AI Evaluation
Practical Solutions and Value
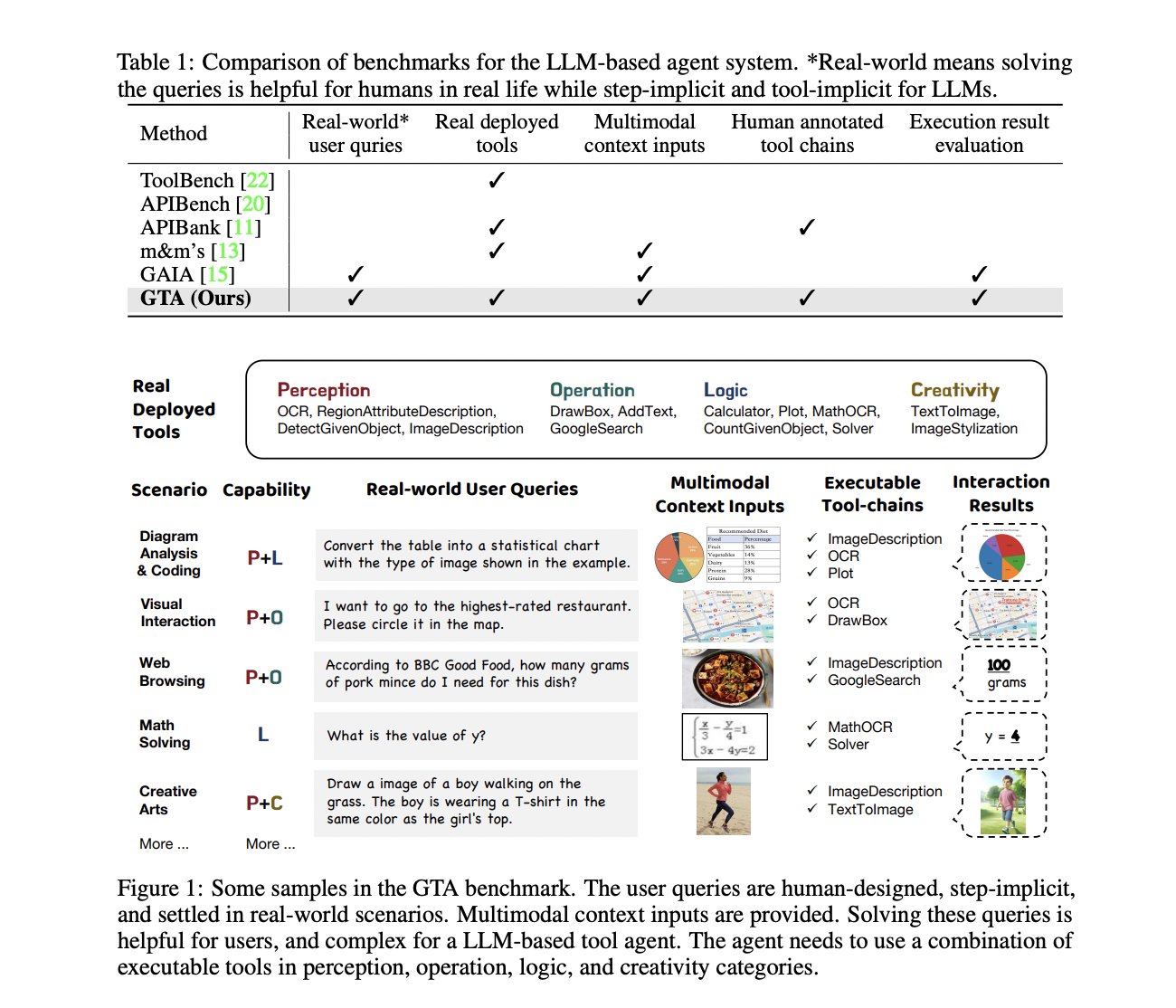
The GTA benchmark addresses the challenge of evaluating large language models (LLMs) in real-world scenarios by providing a more accurate and comprehensive assessment of their tool-use capabilities. It features human-written queries, real deployed tools, and multimodal inputs to closely mimic real-world contexts, allowing for a more realistic evaluation of LLMs in planning and executing complex tasks using various tools.
The benchmark consists of 229 real-world tasks that require the use of various tools, with evaluations conducted in step-by-step and end-to-end modes. The results highlight the shortcomings of current LLMs in handling real-world tool-use tasks and emphasize the need for further advancements in the development of general-purpose tool agents. The GTA benchmark sets a new standard for evaluating LLMs and serves as a crucial guide for future research aimed at enhancing their tool-use proficiency.
Achieving AI Advancements
Evolve your company with AI and stay competitive by leveraging The GTA Benchmark to redefine your work processes. Identify automation opportunities, define KPIs, select appropriate AI solutions, and implement them gradually to drive measurable impacts on business outcomes. For AI KPI management advice and continuous insights into leveraging AI, connect with us at hello@itinai.com and stay tuned on our Telegram or Twitter.
Enhancing Sales Processes and Customer Engagement
Discover how AI can redefine your sales processes and customer engagement. Explore AI solutions at itinai.com.

























