
The article discusses the challenges and solutions for optimizing the performance and cost of running Large Language Models (LLMs). It highlights the high expenses of using OpenAI APIs and the trend of companies hosting their own LLMs to reduce costs. The focus is on algorithmic improvements, software/hardware co-design, and specific techniques such as quantization, attention mechanisms, caching, and speculative sampling to accelerate LLM performance. The upcoming articles will delve into software stack/libraries and hardware architecture considerations for LLM acceleration.
“`html
How to Optimize Large Language Models (LLMs) for Cost and Performance
Leading Large Language Models (LLMs) like ChatGPT, Llama, etc. are revolutionizing the tech industry and impacting everyone’s lives. However, their cost poses a significant hurdle. Applications utilizing OpenAI APIs incur substantial expenses for continuous operation.
Reducing Costs by Hosting Own LLMs
To cut costs, companies tend to host their own LLMs, with expenses varying widely based on model size. This trend has spurred the AI chip race, as major tech companies aim to develop their own AI chips, reducing reliance on expensive hardware.
Optimizing LLMs for Cost and Performance
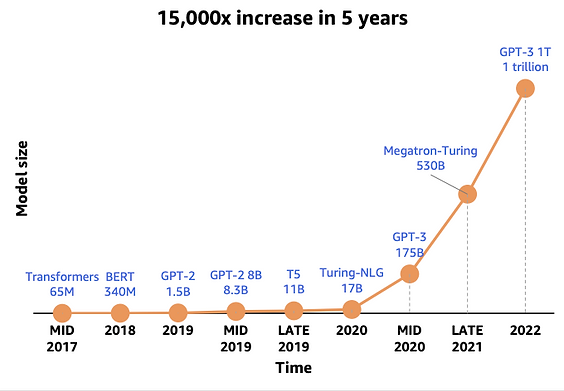
The compute and memory demands of running LLM models are growing exponentially, while computing/memory capabilities are lagging behind on a slower trajectory. To bridge this performance gap, it’s crucial to explore enhancements in three key areas:
- Algorithmic Improvement and Model Compression: Augment models with features to reduce compute and memory demands without compromising quality. Utilize quantization technology to reduce model size while maintaining quality.
- Efficient SW Stack and Acceleration Libraries: Construct a software stack that seamlessly connects AI models and hardware. Expose hardware features to optimize LLM acceleration.
- Powerful AI HW Acceleration and Advanced Memory Hierarchy: Explore contemporary hardware accelerators tailored for LLMs and advancements in memory hierarchy to alleviate high memory demands.
Accelerating Transformer Performance
LLM is based on transformer architecture, and to accelerate transformer performance, we focus on four new features:
- Quantization: Converting FP32 models to INT8 models ideally shrinks memory size by approximately 4x, while INT4 quantization achieves around 8x model size reduction.
- Attention Mechanism: Introduce multi-query attention and flash attention for optimized attention inference.
- Paged KV Cache: Implement Paged Attention to minimize redundancy in KV cache memory and facilitate flexible sharing of KV cache within and across requests.
- Speculative Sampling: Deliver high-quality results akin to large models but with faster speeds similar to smaller models.
Optimizing AI Workloads
Optimizing AI workloads always involves a synergy of model, software, and hardware considerations. In upcoming posts, we’ll dive into the software stack/libraries and hardware architecture aspects for LLM acceleration.
AI Solutions for Your Company
If you want to evolve your company with AI, stay competitive, and use SW/HW Co-optimization Strategy for Large Language Models (LLMs).
Discover Practical AI Solutions
Consider the AI Sales Bot from itinai.com/aisalesbot designed to automate customer engagement 24/7 and manage interactions across all customer journey stages.
For AI KPI management advice, connect with us at hello@itinai.com. And for continuous insights into leveraging AI, stay tuned on our Telegram t.me/itinainews or Twitter @itinaicom.
“`
List of Useful Links:
- AI Lab in Telegram @aiscrumbot – free consultation
- SW/HW Co-optimization Strategy for Large Language Models (LLMs)
- Towards Data Science – Medium
- Twitter – @itinaicom
























