
SuperBPE: Enhancing Language Models with Advanced Tokenization
Introduction to Tokenization Challenges
Language models (LMs) encounter significant challenges in processing textual data due to the limitations of traditional tokenization methods. Current subword tokenizers divide text into vocabulary tokens that cannot span across whitespace, treating spaces as strict boundaries. This approach overlooks the fact that meaning often transcends individual words, as multi-word expressions frequently function as cohesive semantic units. For instance, English speakers commonly use phrases like “a lot of” as single units of meaning. Additionally, different languages express the same concepts using varying numbers of words, with languages such as Chinese and Japanese not using whitespace at all, allowing for more fluid tokenization.
Innovative Approaches to Tokenization
Several research initiatives have explored alternatives to traditional subword tokenization. Some have focused on processing text at multiple levels of granularity or creating multi-word tokens through frequency-based n-gram identification. Others have investigated multi-token prediction (MTP), enabling language models to predict multiple tokens simultaneously. However, these methods often necessitate architectural changes and limit the number of tokens predicted in each step. Additionally, tokenizer-free approaches that model text as byte sequences can lead to longer sequences and increased computational demands, complicating the architecture further.
Introducing SuperBPE
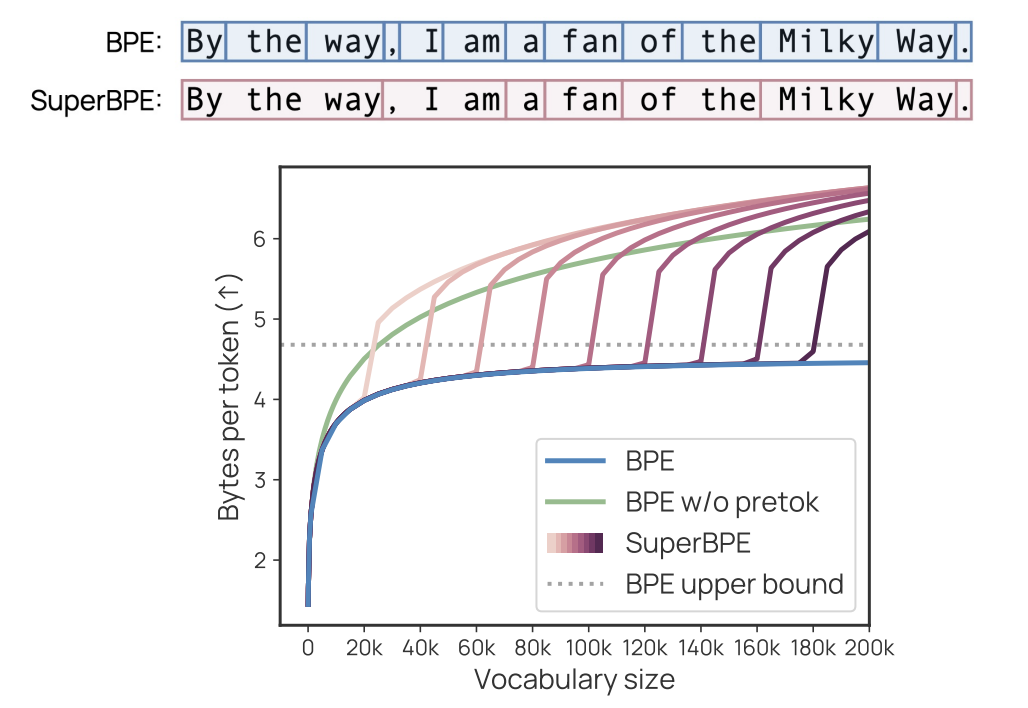
Researchers from the University of Washington, NVIDIA, and the Allen Institute for AI have developed SuperBPE, an innovative tokenization algorithm that combines traditional subword tokens with new tokens that can span multiple words. This method enhances the widely used byte-pair encoding (BPE) algorithm by employing a two-stage training process. Initially, it maintains whitespace boundaries to identify subword tokens, then removes these constraints to facilitate the formation of multi-word tokens. While traditional BPE quickly reaches performance limits and relies on rare subwords as vocabulary grows, SuperBPE continues to identify and encode common multi-word sequences as single tokens, thereby improving encoding efficiency.
Operational Efficiency of SuperBPE
SuperBPE operates through a two-stage training process that modifies the pretokenization phase of traditional BPE. This method effectively builds semantic units and combines them into common sequences, enhancing efficiency. By adjusting the transition point during training, users can either achieve standard BPE or a more naive whitespace-free BPE. Although SuperBPE requires more computational resources than standard BPE, the training process is efficient, taking only a few hours on 100 CPUs—a minor investment compared to the resources needed for language model pretraining.
Performance Metrics and Case Studies
SuperBPE demonstrates exceptional performance across 30 benchmarks, including knowledge, reasoning, coding, and reading comprehension tasks. All models utilizing SuperBPE outperform the BPE baseline, with the most robust 8B model achieving an average improvement of 4.0% and excelling in 25 out of 30 individual tasks. Notably, multiple-choice tasks exhibit a remarkable +9.7% improvement. The only significant drop occurs in the LAMBADA task, where accuracy decreases from 75.8% to 70.6%. Importantly, all reasonable transition points yield stronger results than the baseline, with the most efficient point providing a +3.1% performance boost while reducing inference computation by 35%.
Conclusion
In summary, SuperBPE represents a significant advancement in tokenization techniques, enhancing the traditional BPE algorithm by incorporating multi-word tokens. This innovative approach recognizes that tokens can extend beyond conventional subword boundaries to include multi-word expressions. By enabling language models to achieve superior performance across various tasks while simultaneously reducing computational costs, SuperBPE serves as an effective replacement for traditional BPE in modern language model development. Its implementation requires no alterations to existing model architectures, making it a seamless integration into current workflows.
Next Steps for Businesses
To leverage the benefits of AI and advanced tokenization like SuperBPE, businesses should:
- Explore areas where AI can automate processes and enhance customer interactions.
- Identify key performance indicators (KPIs) to measure the impact of AI investments.
- Select tools that align with business objectives and allow for customization.
- Start with small-scale projects, evaluate their effectiveness, and gradually expand AI applications.
For guidance on integrating AI into your business, please contact us at hello@itinai.ru or connect with us on Telegram, X, and LinkedIn.























