
Strategic Chain-of-Thought (SCoT): An Innovative Approach to Enhancing Large Language Model (LLM) Performance and Reasoning
Improving Reasoning with SCoT
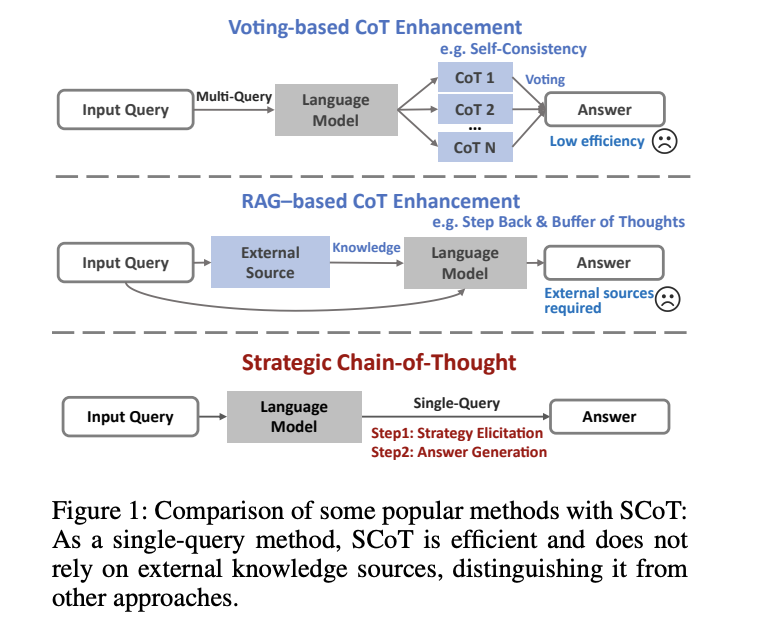
SCoT introduces a strategic method of reasoning, enhancing the quality and consistency of reasoning in LLMs. It ensures that the model’s intermediate steps make sense and align with efficient problem-solving techniques.
Results and Performance
Experiments have demonstrated significant performance gains with SCoT, showing improvements in accuracy across various reasoning datasets. The adaptability of SCoT has been proven in different reasoning scenarios.
Enhanced Capabilities with Few-Shot Learning
SCoT has been expanded to include a few-shot learning technique, allowing the model to draw from relevant examples for tasks based on strategic knowledge. This extension has shown improved adaptability in managing reasoning tasks with less data.
Primary Contributions
SCoT guarantees better results by incorporating strategic information into the reasoning process. It also aligns high-quality CoT examples, enhancing the model’s performance in example-driven reasoning tasks. Extensive studies have verified the efficacy of SCoT in improving LLM reasoning abilities across various domains.
Conclusion
SCoT overcomes the drawbacks of conventional CoT techniques by incorporating strategic information, increasing reasoning precision, and transforming the way LLMs tackle challenging reasoning assignments.
For more information and to stay updated with our latest developments, follow us on Twitter and join our Telegram Channel and LinkedIn Group.

























