Understanding In-Context Reinforcement Learning (ICRL)
Large Language Models (LLMs) are showing great promise in a new area called In-Context Reinforcement Learning (ICRL). This method allows AI to learn from interactions without changing its core parameters, similar to how it learns from examples in supervised learning.
Key Innovations in ICRL
Researchers are tackling challenges in adapting LLMs for ICRL by introducing two main innovations:
- Exploration Problem: By adding randomness to how prompts are created, LLMs can better explore different responses.
- Learning Simplification: Negative examples are filtered out, making the learning process more straightforward and similar to traditional methods.
Practical Benefits of ICRL
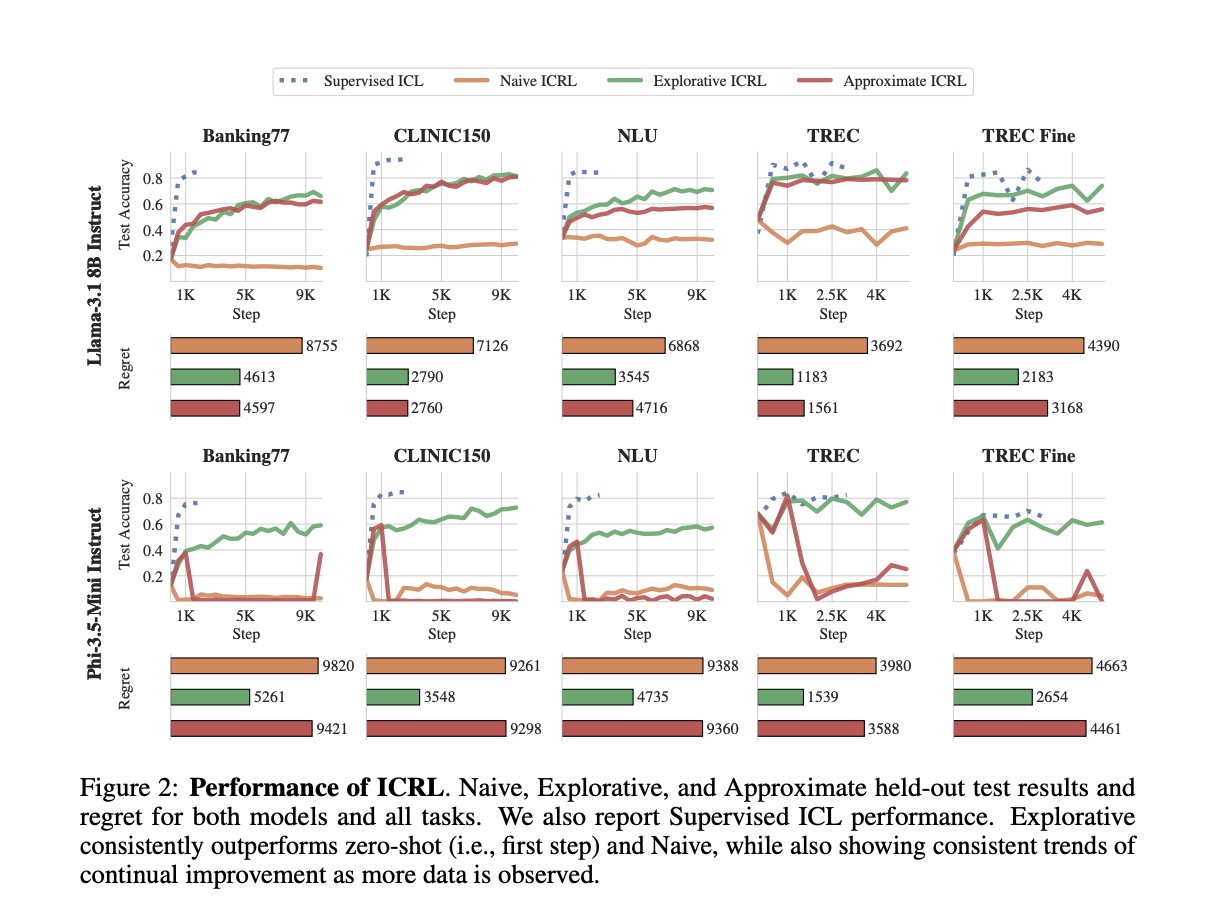
This new approach has shown significant improvements in various tasks. For example, Llama’s accuracy on the Banking77 classification task jumped from 17.2% to 66.0% using ICRL. This demonstrates the method’s effectiveness across different LLM architectures.
Two Approaches to ICRL
Naive ICRL
This basic method involves the model observing new examples, predicting outcomes, and receiving rewards. However, it struggles with exploring different outputs effectively.
Explorative ICRL
This advanced method improves upon Naive ICRL by:
- Incorporating Stochasticity: Randomly selecting past episodes to enhance exploration.
- Focusing on Positive Reinforcement: Only including episodes with positive rewards, simplifying the learning process.
Results and Performance
Explorative ICRL has consistently outperformed zero-shot learning methods, showing remarkable improvements in accuracy across various tasks. For instance, it improved Llama’s accuracy by 48.8% on Banking-77 and 56.8% on Clinic-150.
Challenges and Future Directions
While the Explorative ICRL method is effective, it does come with higher computational costs. Researchers are exploring ways to optimize these methods for better efficiency and to tackle more complex problem domains.
How AI Can Transform Your Business
To leverage these advancements in AI, consider the following steps:
- Identify Automation Opportunities: Find areas in customer interactions that can benefit from AI.
- Define KPIs: Ensure that your AI initiatives have measurable impacts.
- Select an AI Solution: Choose tools that fit your needs and allow for customization.
- Implement Gradually: Start small, gather data, and expand your AI usage wisely.
For more insights and assistance in implementing AI solutions, connect with us at hello@itinai.com. Stay updated by following us on Telegram or @itinaicom.
Join the Conversation
Don’t forget to check out our newsletter and join our community on ML SubReddit with over 50k members.
For more information on how to evolve your company with AI, visit itinai.com.



