
Transforming Natural Language Queries into SQL with SQL-R1
Introduction to NL2SQL
Natural Language to SQL (NL2SQL) technology enables users to interact with databases using everyday language. This innovation is crucial for enhancing data accessibility for non-technical users across various sectors, including finance, healthcare, and retail. As large language models (LLMs) have evolved, they have significantly improved the accuracy and context-awareness of these translations, particularly for simpler queries.
The Challenge of Complex Queries
Despite advancements, accurately converting natural language into SQL remains a challenge, especially in complex scenarios that involve multiple table joins or nested queries. The primary difficulty lies in generating queries that not only adhere to syntax rules but also align with the user’s intent. Traditional systems, which often depend on fixed schemas, struggle to adapt in high-stakes environments where precision and interpretability are paramount.
Limitations of Current Models
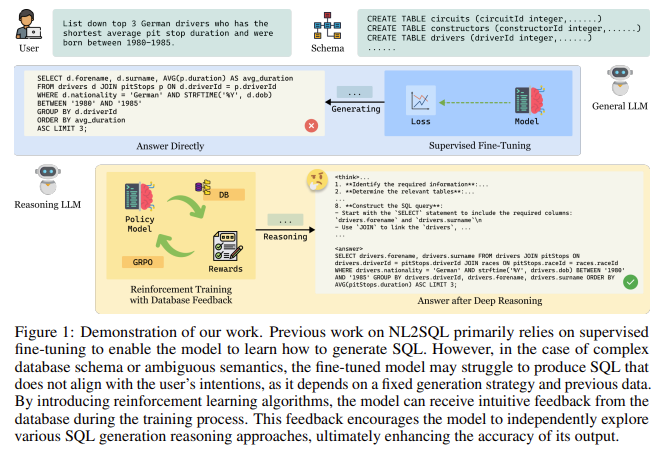
Most existing NL2SQL systems utilize supervised fine-tuning, training on specific annotated datasets. While this method has improved performance, it also limits adaptability and transparency, resulting in poor performance in unfamiliar contexts. Additionally, these models typically lack interpretability, which is essential for industries that require clear decision-making processes.
Introducing SQL-R1
SQL-R1, developed by researchers from IDEA Research and several academic institutions, offers a groundbreaking approach by employing reinforcement learning instead of traditional supervised learning. This model enhances its capabilities through a dynamic feedback mechanism during training, which allows it to generate SQL candidates, execute them, and receive structured feedback on their performance.
Key Features of SQL-R1
- Dynamic Learning: SQL-R1 learns from both success and failure, refining its SQL generation strategies over time.
- Comprehensive Training: The model was initially fine-tuned using 200,000 samples from a synthetic dataset, followed by reinforcement learning on complex samples.
- Effective Reward Mechanism: It employs a scoring system that evaluates SQL candidates based on format, execution, result accuracy, and reasoning clarity.
Performance Metrics
SQL-R1 has demonstrated impressive results in industry-standard benchmarks:
- 88.7% execution accuracy on the Spider test set.
- 66.6% accuracy on the BIRD dataset, which comprises 95 databases across 37 domains.
These results position SQL-R1 as competitive, even outperforming larger models like GPT-4, showcasing that effective architecture and reinforcement learning can yield high accuracy without relying on extensive model size.
Case Studies and Implications
By leveraging SQL-R1, businesses can achieve significant improvements in data query processes, enhancing operational efficiency and decision-making. For example, a financial institution could automate complex reporting tasks, allowing analysts to focus on strategic insights rather than data retrieval. Similarly, healthcare providers could streamline patient data access, ultimately improving care delivery.
Conclusion
SQL-R1 represents a significant advancement in the field of artificial intelligence, particularly in transforming natural language queries into accurate SQL commands. By enhancing adaptability, interpretability, and performance, SQL-R1 empowers businesses to harness the full potential of their data resources. As organizations increasingly rely on data-driven decision-making, adopting such innovative technologies will be crucial for maintaining a competitive edge.



