
Practical Solutions and Value of High-Quality Data in Pretraining Code Models
Challenges in Code Model Development
Machine learning models, especially those designed for code generation, heavily depend on high-quality data during pretraining. This field has seen rapid advancement, with large language models (LLMs) trained on extensive datasets containing code from various sources. The challenge for researchers is to ensure that the data used is abundant and of high quality, as this significantly impacts the model’s ability to handle complex tasks. In code-related applications, well-structured, annotated, and clean data ensures that models can generate accurate, efficient, and reliable outputs for real-world programming tasks.
Importance of Data Quality
A significant issue in code model development is the lack of precise definitions of “high-quality” data. While vast amounts of code data are available, much contains noise, redundancy, or irrelevant information, which can degrade model performance. Relying on raw data, even after filtering, often leads to inefficiencies. To address this, there has been an increased focus on not just acquiring large amounts of data but curating data that aligns well with downstream applications, improving the model’s predictive abilities and overall utility.
Refined Pretraining Approach
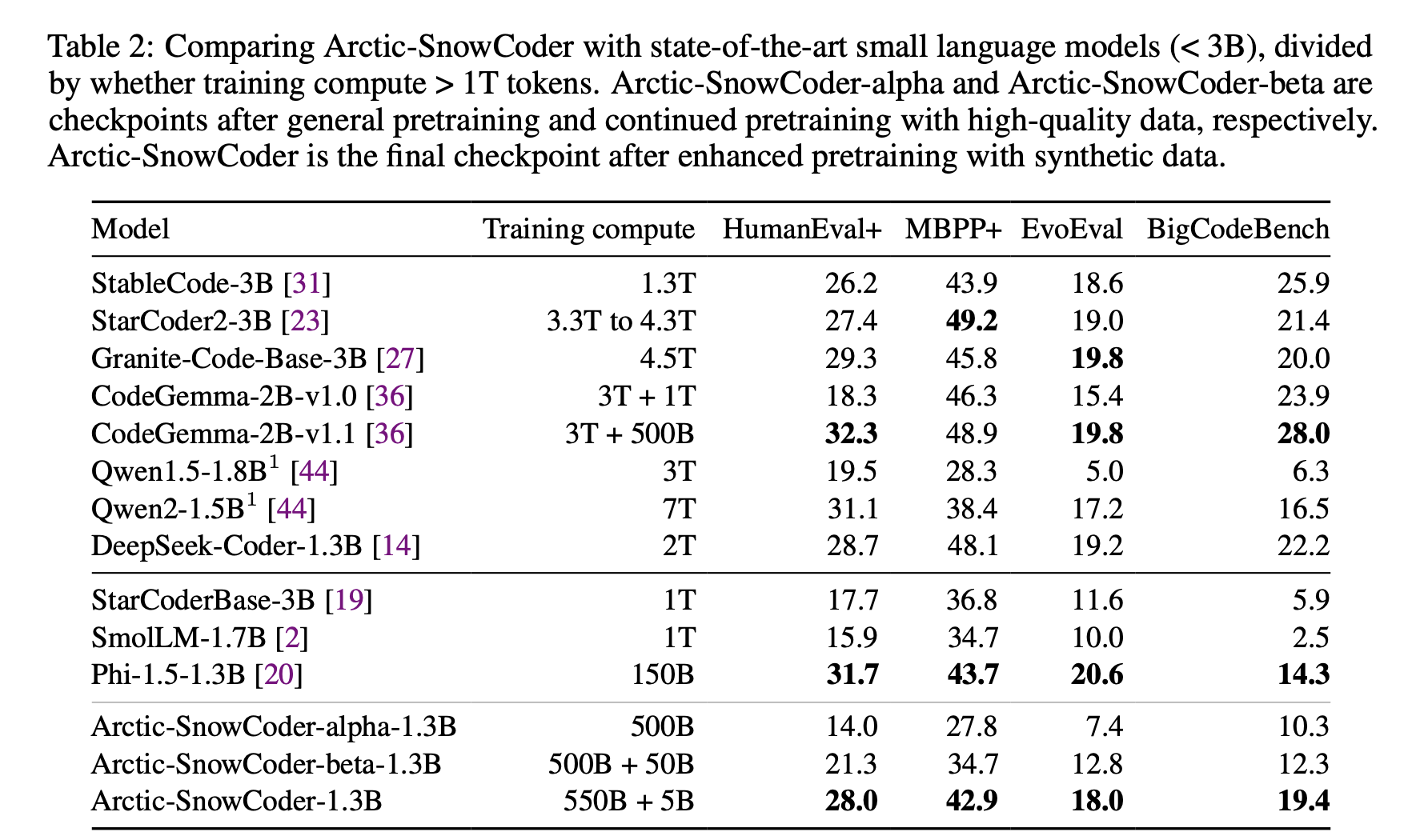
Historically, the pretraining of code models involved scraping large repositories such as GitHub and processing raw data through basic filtering and deduplication techniques. Newer approaches have adopted more sophisticated tools, such as BERT-based annotators, to classify code quality and select data that would more effectively contribute to the model’s success. The research team from Snowflake AI Research, University of Illinois at Urbana-Champaign, and Seoul National University introduced Arctic-SnowCoder-1.3B, a novel approach to pretraining code models by progressively refining data quality over three distinct phases. This method combined general pretraining, continued pretraining with high-quality data, and final pretraining with synthetic data, resulting in a model that outperformed its competitors.
Enhanced Model Performance
The effectiveness of this approach is evident in Arctic-SnowCoder-1.3B’s results. Despite being trained on only 555 billion tokens, it significantly outperformed other models of similar size, surpassing larger models trained on over 1 trillion tokens. On practical benchmarks, Arctic-SnowCoder exceeded the performance of other models by a significant margin, highlighting the importance of data quality over quantity in pretraining code models.
Conclusion and Practical Guidelines
In conclusion, Arctic-SnowCoder-1.3B illustrates the critical role of progressively refined, high-quality data in the pretraining of code models. This method demonstrates the importance of aligning pretraining data with downstream tasks and provides practical guidelines for future model development. Arctic-SnowCoder’s success is a testament to the value of high-quality data, showing that careful data curation and synthetic data generation can lead to substantial improvements in code generation models.
Connect with Us
If you want to evolve your company with AI, stay competitive, use for your advantage Snowflake AI Research Introduces Arctic-SnowCoder-1.3B: A New 1.3B Model that is SOTA Among Small Language Models for Code. For AI KPI management advice, connect with us at hello@itinai.com. And for continuous insights into leveraging AI, stay tuned on our Telegram t.me/itinainews or Twitter @itinaicom.


























