
Understanding the Challenges in Evaluating NLP Models
Evaluating Natural Language Processing (NLP) models is becoming more complicated. Key issues include:
- Benchmark Saturation: Many models now perform at near-human levels, making it hard to distinguish between them.
- Data Contamination: Ensuring evaluation data is completely human-made is increasingly difficult.
- Variable Test Quality: The quality of tests can differ greatly, affecting reliability.
Practical Solution: Dataset Filtering
One effective way to address these challenges is through dataset filtering. This revitalizes existing benchmarks and offers a practical alternative to developing new datasets.
Recent Benchmark Datasets
New datasets like MMLU, GSM8K, MATH, and GPQA have been created to test language models. However, they face reliability issues:
- Annotation Errors: Mistakes in labeling can skew results.
- Answer Order Sensitivity: Results can vary based on how answers are presented.
- Biases in Models: Models may perform well not due to ability but because of biases in data.
Improving Reliability
A proposed solution is filtering out easier examples from datasets. Unlike past methods that required retraining and human checks, this approach efficiently identifies high-quality subsets.
Introducing SMART Filtering
Researchers from Meta AI, Pennsylvania State University, and UC Berkeley have developed SMART filtering. This method improves benchmark datasets by:
- Removing overly easy or contaminated examples.
- Identifying high-quality datasets without needing human oversight.
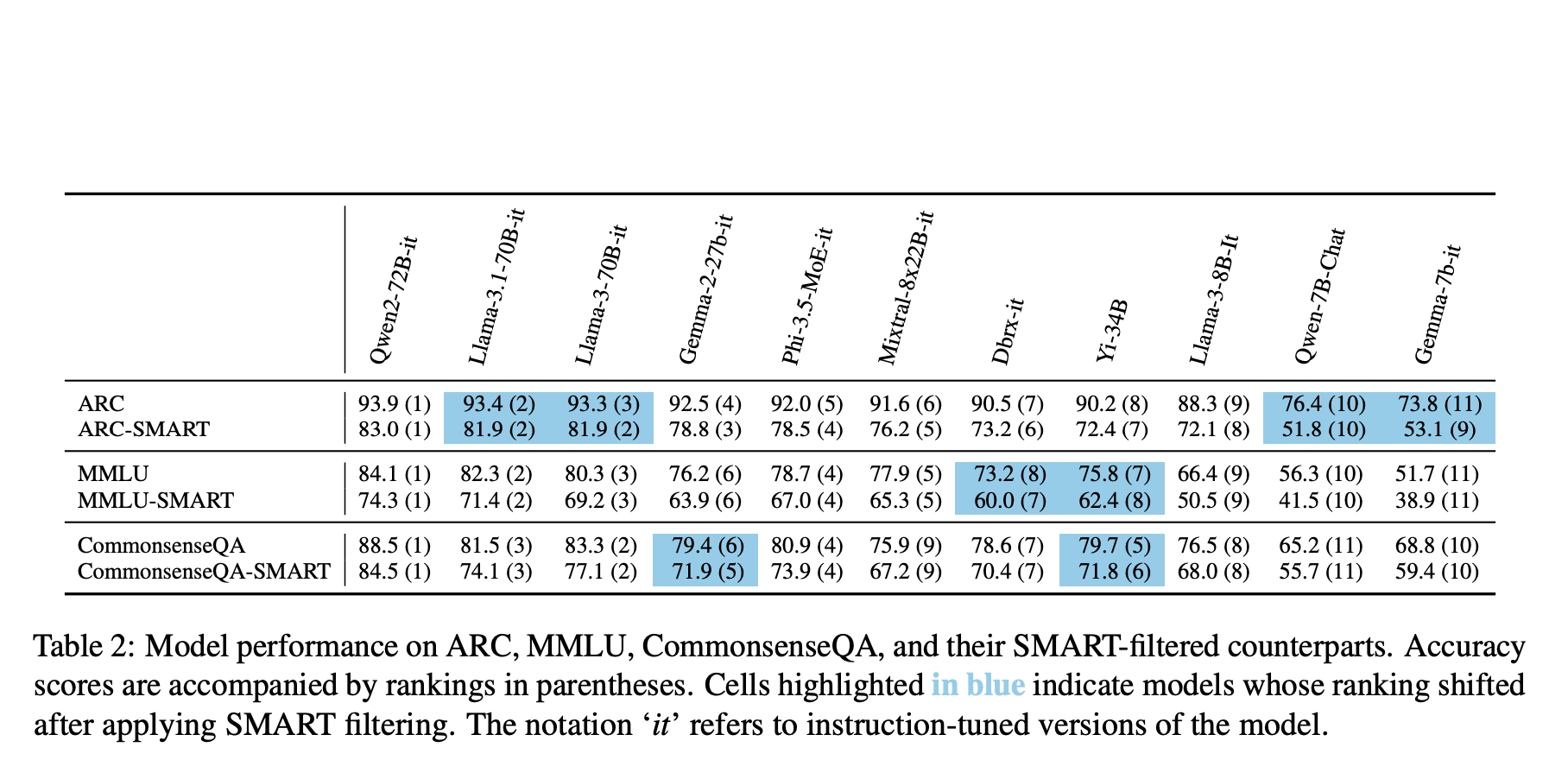
In tests on datasets like ARC, MMLU, and CommonsenseQA, SMART filtering reduced dataset sizes by an average of 48% while maintaining or improving model ranking consistency.
Steps in SMART Filtering
SMART filtering uses three steps to refine datasets:
- Remove Easy Examples: Eliminate questions that top models answer correctly with high confidence.
- Filter Contaminated Data: Remove examples likely seen during training.
- Deduplicate Similar Examples: Identify and eliminate redundant examples using embeddings.
This process enhances the challenge of the dataset while reducing computational costs.
Efficiency Across Datasets
SMART filtering has been shown to significantly improve efficiency in multiple-choice question-answering datasets. For instance:
- ARC size was reduced by up to 68.9% while keeping model rankings intact.
- A substantial portion of ARC and MMLU datasets contained easy or contaminated questions.
The method aligns well with human evaluations from ChatBot Arena, validating its effectiveness.
Applying SMART Filtering
This technique can be used pre- or post-release of datasets and can adapt to new models. It significantly cuts evaluation costs while maintaining model ranking accuracy.
Next Steps for Your Business
To leverage AI effectively, consider these steps:
- Identify Automation Opportunities: Find areas in customer interactions that can benefit from AI.
- Define KPIs: Establish measurable impacts for your AI projects.
- Select an AI Solution: Choose tools that meet your needs and allow for customization.
- Implement Gradually: Start small, gather data, and expand AI usage wisely.
For further insights on AI KPI management, contact us at hello@itinai.com. Stay updated on leveraging AI by following us on Telegram or @itinaicom.
Explore More
For more information on how AI can transform your business processes, visit itinai.com.





















