
Introduction to SimLayerKV
Recent improvements in large language models (LLMs) have made them better at handling long contexts, which is useful for tasks like answering questions and complex reasoning. However, a significant challenge has arisen: the memory needed for storing key-value (KV) caches increases dramatically as model layers and input lengths grow. This KV cache stores important data to speed up processing but requires a lot of GPU memory, making it hard to use these models on a large scale.
Understanding the Problem
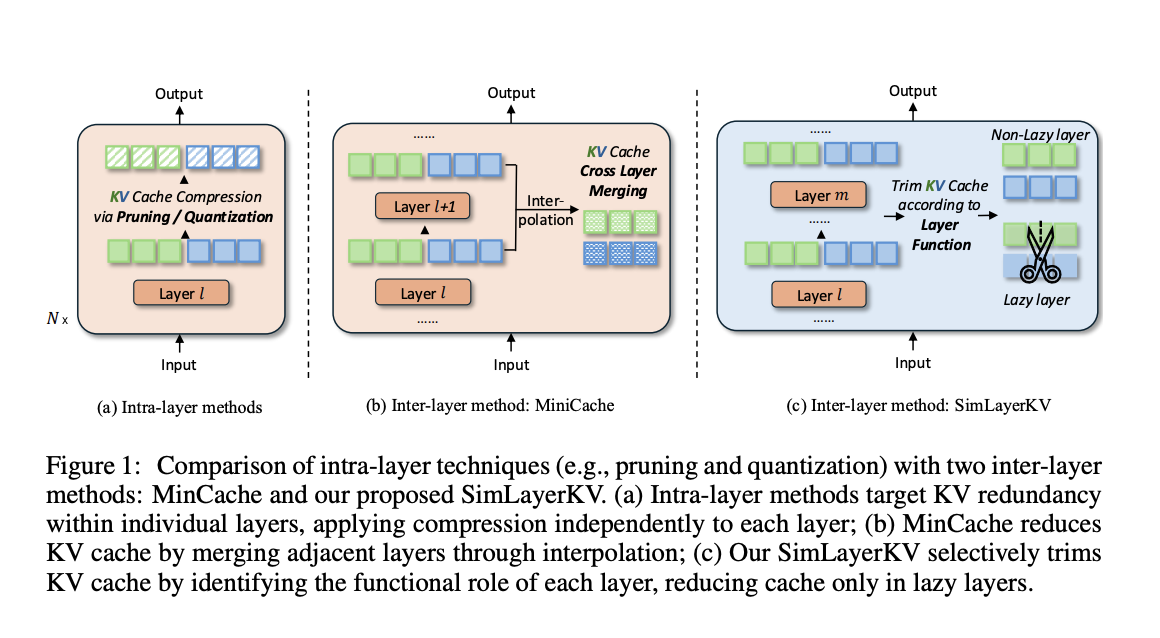
For example, the LLaMA2-7B model needs about 62.5 GB of GPU memory for its KV cache when processing 128K tokens. Current methods to optimize this cache mainly focus on reducing memory within individual layers, missing out on potential savings across different layers.
Introducing SimLayerKV
Researchers from Sea AI Lab and Singapore Management University have developed SimLayerKV, a new method that reduces memory use by targeting redundancies between layers. They found that some layers in long-context LLMs are “lazy,” meaning they contribute less to understanding long-range dependencies. These layers often focus on less important or just recent tokens.
How SimLayerKV Works
SimLayerKV identifies these lazy layers by analyzing how they allocate attention. It reduces the KV cache for these layers while keeping the full cache for more important layers. This method is easy to implement, needing only seven lines of code, and works well with 4-bit quantization for even more memory savings.
Results and Benefits
In tests with LLaMA2-7B, LLaMA3-8B, and Mistral-7B models, SimLayerKV achieved a KV cache compression ratio of 5× with only a 1.2% drop in performance. For instance, Mistral-7B maintained strong performance while using less memory. In specific tasks, like the Needle-in-a-Haystack (NIAH) task, it showed only a 4.4% performance drop, demonstrating its efficiency.
Practical Solutions and Value
SimLayerKV offers a straightforward way to address the KV cache memory issue in large LLMs. By trimming unnecessary cache from lazy layers, it provides significant memory savings without greatly affecting performance. Its easy integration makes it a valuable tool for improving the efficiency of models that work with long contexts.
Future Opportunities
Combining SimLayerKV with other optimization techniques could further enhance memory efficiency and model performance, opening new possibilities for deploying LLMs effectively.
Get Involved
Check out the Paper and GitHub for more details. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. If you enjoy our work, subscribe to our newsletter and join our 50k+ ML SubReddit.
Upcoming Live Webinar
Oct 29, 2024 – The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Transform Your Business with AI
To stay competitive, leverage SimLayerKV to overcome KV cache challenges in large LLMs. Discover how AI can transform your operations:
- Identify Automation Opportunities: Find key customer interactions that can benefit from AI.
- Define KPIs: Ensure measurable impacts from your AI initiatives.
- Select an AI Solution: Choose tools that fit your needs and allow customization.
- Implement Gradually: Start small, gather data, and expand AI usage wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights into leveraging AI, follow us on Telegram at t.me/itinainews or Twitter at @itinaicom.
Enhance Your Sales and Customer Engagement
Explore AI solutions to redefine your sales processes and customer interactions at itinai.com.


























