
Show-o: A Unified AI Model that Unifies Multimodal Understanding and Generation Using One Single Transformer
Practical Solutions and Value
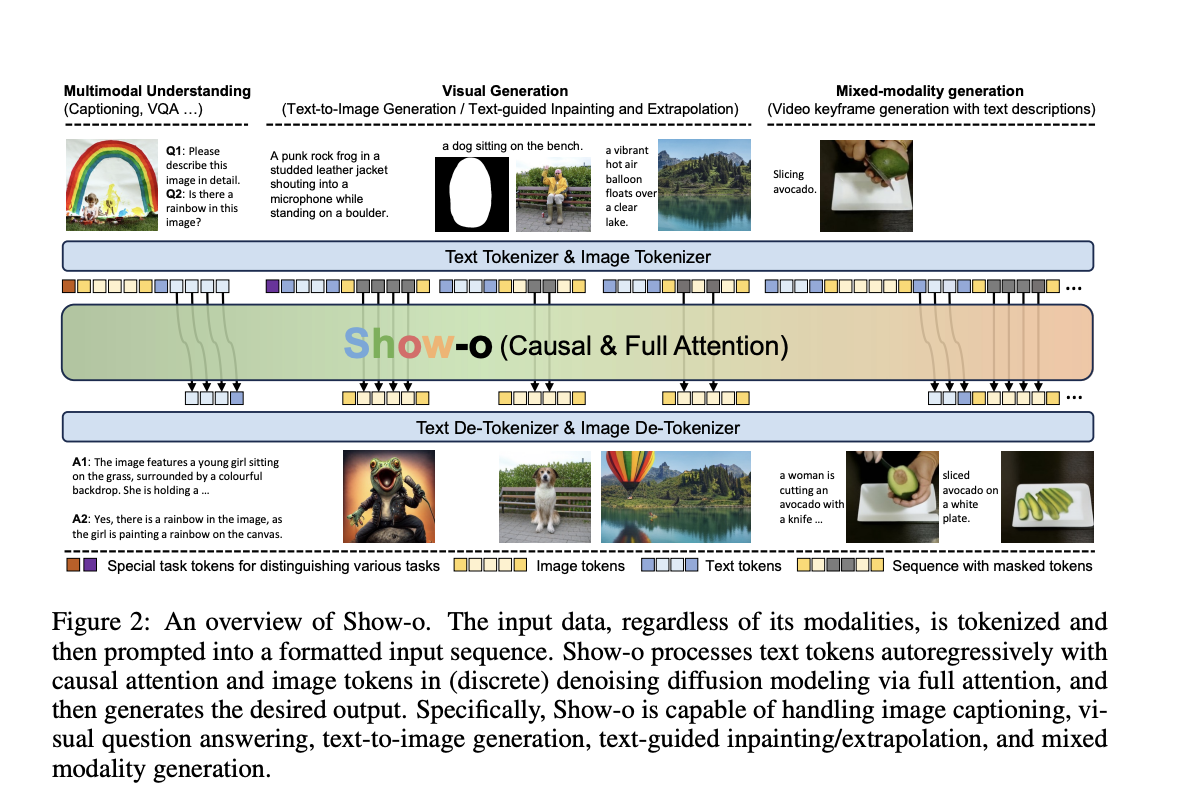
This paper presents Show-o, a transformer model that combines multimodal understanding and generation capabilities in one architecture. It addresses the challenge of unifying text and image processing effectively.
Show-o offers a practical solution by incorporating autoregressive text modeling and discrete denoising diffusion for images, allowing it to handle diverse input types and generate various outputs, including text responses, photos, and mixed-modality content.
The model demonstrates impressive performance across various benchmarks, achieving comparable or superior results to specialized models despite having fewer parameters. It also exhibits capabilities in downstream tasks like text-guided image inpainting and mixed-modality generation.
Show-o simplifies the model architecture and enables new possibilities in mixed-modality tasks and efficient downstream applications. It represents a significant advancement in multimodal AI by unifying understanding and generation capabilities within a single, efficient transformer architecture.
AI Solutions for Business
If you want to evolve your company with AI, stay competitive, and use Show-o to redefine your way of work. To leverage AI effectively, consider the following:
- Identify Automation Opportunities: Locate key customer interaction points that can benefit from AI.
- Define KPIs: Ensure your AI endeavors have measurable impacts on business outcomes.
- Select an AI Solution: Choose tools that align with your needs and provide customization.
- Implement Gradually: Start with a pilot, gather data, and expand AI usage judiciously.
For AI KPI management advice, connect with us at hello@itinai.com. For continuous insights into leveraging AI, stay tuned on our Telegram or Twitter.
Discover how AI can redefine your sales processes and customer engagement. Explore solutions at itinai.com.

























