
Understanding ShadowKV: A Solution for Long-Context LLMs
Challenges with Long-Context LLMs
Large language models (LLMs) are improving in handling longer texts. However, serving these models efficiently is challenging due to memory issues and slow processing speeds. The key-value (KV) cache, which stores previous data to avoid re-computation, becomes large and slows down performance as text length increases.
Common Issues
Existing methods face three main problems:
– **Accuracy Loss**: Deleting old cache data can hurt performance, especially in conversations.
– **Memory Inefficiency**: Current strategies do not sufficiently reduce memory use.
– **Slow Processing**: Moving data between GPU and CPU slows down operations.
Innovative Solutions
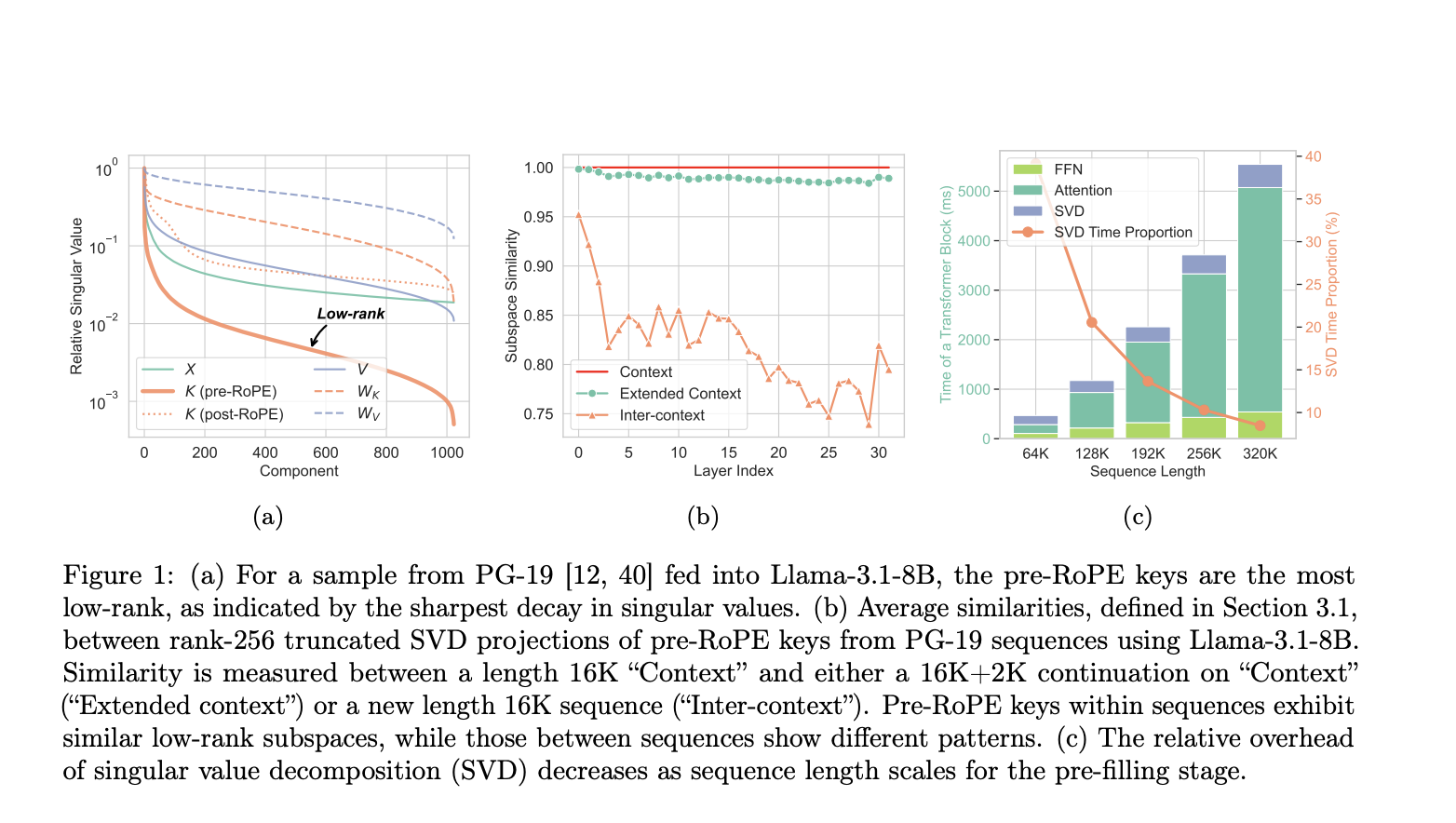
Pre-RoPE keys are simpler data structures that can be efficiently compressed. This allows important data to remain on the GPU while less critical data is stored on the CPU without significantly affecting speed or accuracy. This method enhances the processing of long texts with LLMs by optimizing memory usage.
Introducing ShadowKV
Researchers from Carnegie Mellon University and ByteDance developed **ShadowKV**, a high-throughput inference system. It effectively reduces memory use by storing low-rank key caches and offloading value caches. This allows for larger batch sizes and shorter decoding times.
How ShadowKV Works
ShadowKV operates in two phases:
1. **Pre-Filling Phase**: It compresses key caches and moves value caches to CPU memory. It uses techniques like Singular Value Decomposition (SVD) to optimize data storage.
2. **Decoding Phase**: It calculates attention scores efficiently, reducing computation by 60% and only creating necessary KV pairs.
ShadowKV achieves impressive data loading speeds, reaching a bandwidth of 7.2 TB/s on an A100 GPU, significantly surpassing its memory bandwidth.
Proven Performance
Tests on various benchmarks show that ShadowKV can handle up to six times larger batch sizes, outperforming traditional methods even with limited GPU memory.
Conclusion
ShadowKV is a promising system for enhancing long-context LLM inference. It optimizes memory use and speeds up processing while maintaining accuracy. This innovation is a significant step forward in the field of large language models.
Get Involved
Explore the research paper and GitHub page for more details. Follow us on Twitter, join our Telegram channel, and connect on LinkedIn. If you appreciate our work, consider subscribing to our newsletter and joining our active ML SubReddit community.
Partner with Us
Promote your research, product, or webinar to over a million monthly readers and a community of 500k+ members.
Transform Your Business with AI
Leverage ShadowKV to enhance your company’s AI capabilities:
– **Identify Automation Opportunities**: Find key areas for AI integration.
– **Define KPIs**: Measure the impact of AI on your business.
– **Select the Right AI Solution**: Choose tools that fit your needs.
– **Implement Gradually**: Start small, gather data, and scale wisely.
For AI management advice, reach out to us at hello@itinai.com, and stay updated on AI insights through our Telegram and Twitter channels. Discover how AI can revolutionize your sales and customer engagement at itinai.com.

























