
Practical Solutions for Video Processing Challenges
Introduction
Video large language models (LLMs) are powerful tools for processing video inputs and generating contextually relevant responses to user commands. However, they face challenges in training costs and processing limitations.
Research Efforts
Researchers have explored various LLM approaches to solve video processing challenges, with some successful models requiring expensive fine-tuning on large video datasets.
Introducing SF-LLaVA
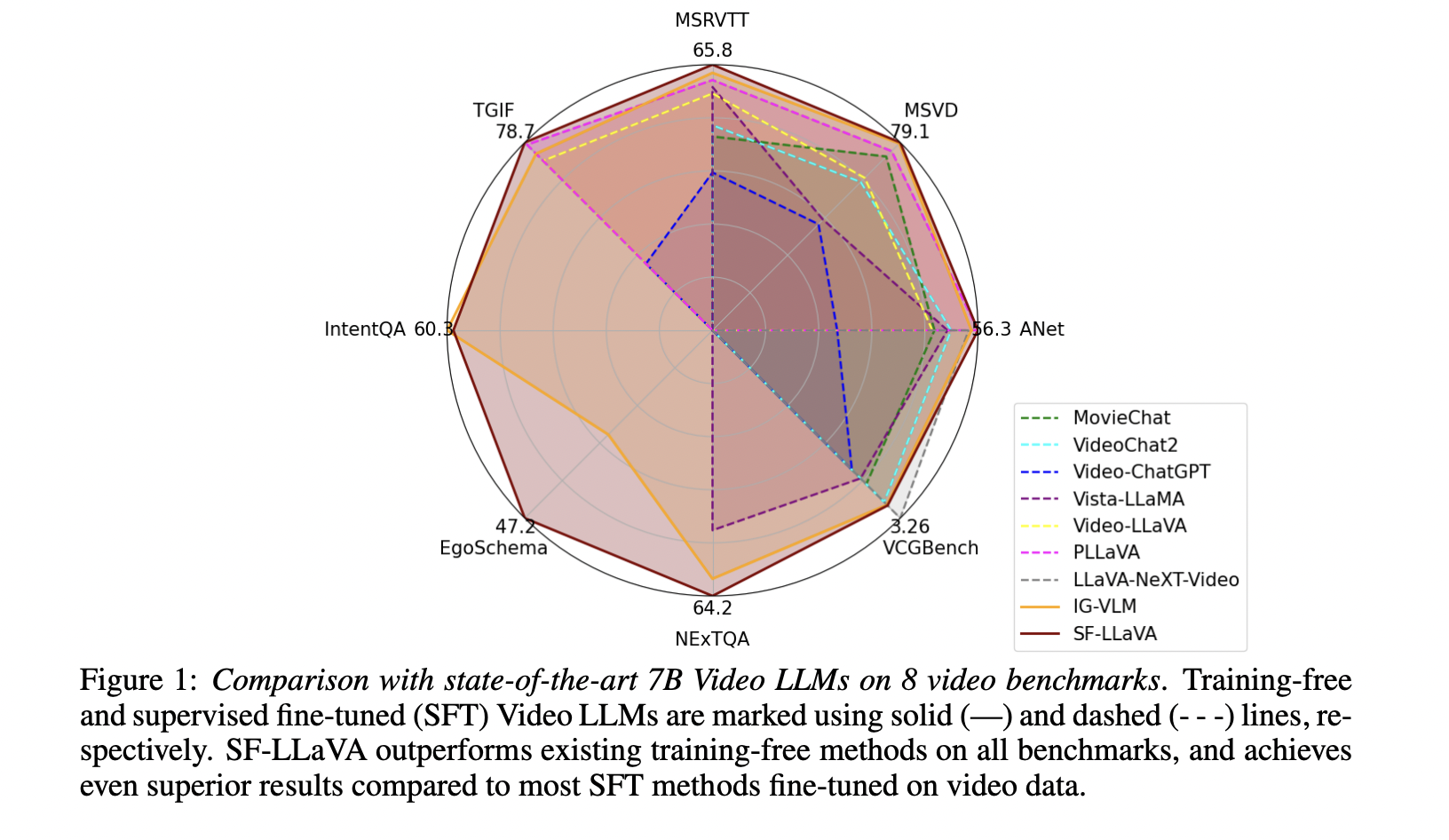
SF-LLaVA is a unique training-free Video LLM that effectively addresses video processing challenges. It introduces a SlowFast design inspired by successful two-stream networks for action recognition, capturing both spatial semantics and long-range temporal context without additional fine-tuning.
Performance and Impact
SF-LLaVA demonstrates impressive performance across various video understanding tasks, often surpassing state-of-the-art training-free methods and competing with supervised fine-tuned models.
Value and Future Insights
SF-LLaVA offers valuable insights for future research in modeling video representations for Multimodal LLMs through its design choices, serving as a strong baseline and redefining video understanding without additional fine-tuning.
Call to Action
Evolve your company with AI, stay competitive, and benefit from SF-LLaVA for various video tasks. Identify automation opportunities, define KPIs, select the right AI solution, and implement gradually to leverage AI’s potential for your business.
Connect with Us
For AI KPI management advice and continuous insights into leveraging AI, connect with us at hello@itinai.com. Follow us on Telegram t.me/itinainews or Twitter @itinaicom for the latest updates.

























