
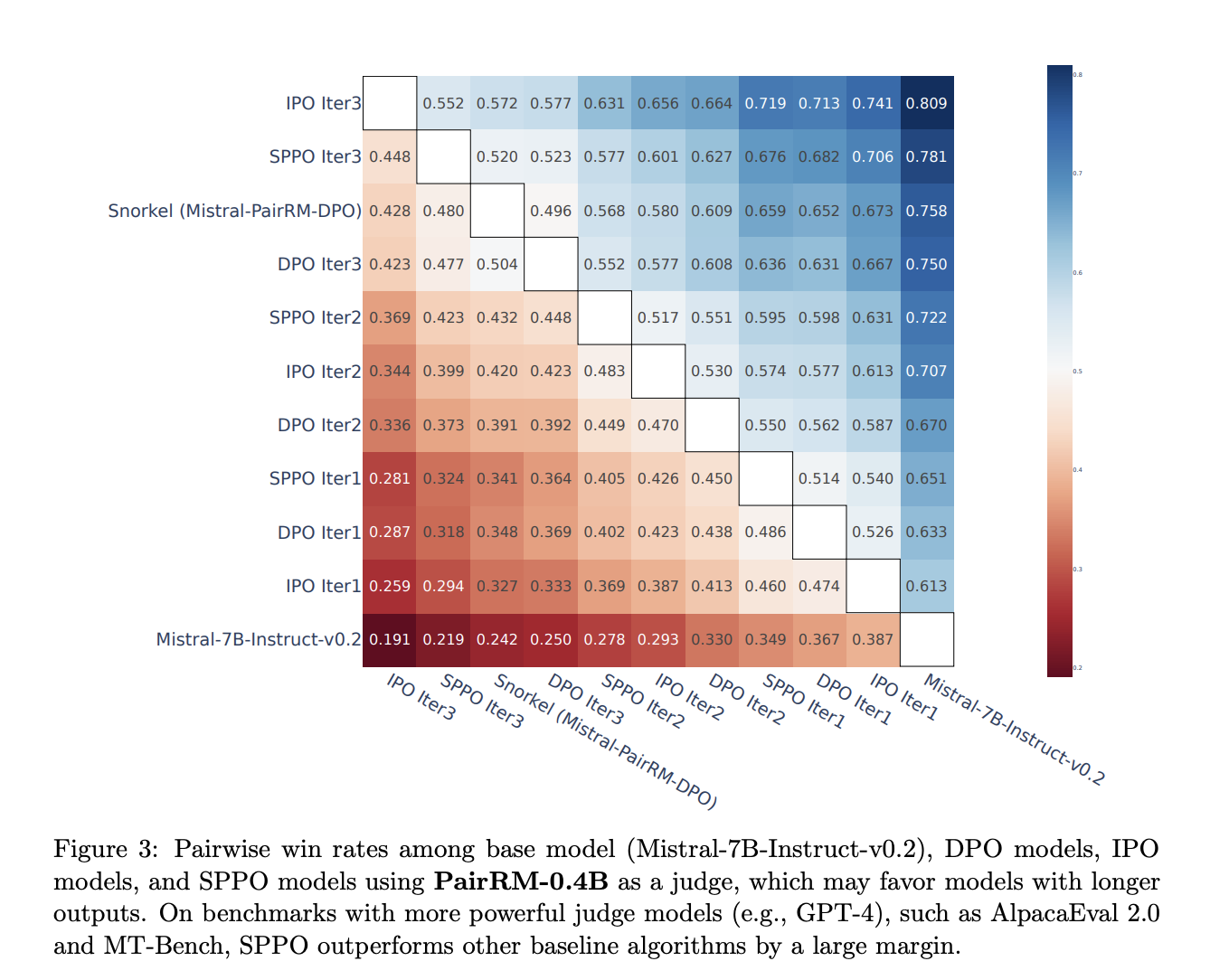
<>
Self-Play Preference Optimization (SPPO): A Solution for Fine-Tuning Large Language Models (LLMs)
Large Language Models (LLMs) have shown impressive capabilities in generating human-like text, answering questions, and coding. However, they face challenges in reliability, safety, and ethical adherence. Self-Play Preference Optimization (SPPO) emerges as a promising solution for aligning LLMs with human preferences and enhancing their usefulness.
Key Features of SPPO
- Robust self-play framework
- Provable guarantees for solving two-player constant-sum games
- Scalability for large language models
- Adaptive algorithm based on multiplicative weights
Benefits of SPPO
- Improved convergence compared to existing methods
- Efficiently addresses data sparsity issues
- Consistently improves model performance across iterations
- Controls output length effectively
SPPO models consistently outperform state-of-the-art chatbots on AlpacaEval 2.0 and remain competitive with GPT-4 on MT-Bench. The method significantly enhances generative AI system alignment and advocates for broader adoption in LLMs and beyond.
For more details, check out the Paper.
Evolving Your Company with AI
Utilize Self-Play Preference Optimization (SPPO) to stay competitive and redefine your work processes. Identify automation opportunities, define KPIs, select AI solutions, and implement gradually for impactful business outcomes.
AI Automation Opportunities
- Locate key customer interaction points for AI integration
AI Solution Selection
- Choose tools that align with your needs and offer customization
Connect with us at hello@itinai.com for AI KPI management advice. Stay tuned for continuous insights into leveraging AI on Telegram or Twitter.
Practical AI Solution Spotlight: AI Sales Bot
Explore the AI Sales Bot from itinai.com/aisalesbot designed to automate customer engagement 24/7 and manage interactions across all customer journey stages.

























