
Challenges in Deploying Large Language Models (LLMs)
The growing size of Large Language Models (LLMs) makes them hard to use in practical applications. They consume a lot of energy and take time to process due to high memory needs. This limits their use on devices with limited memory. Although post-training compression can help, many methods require calibration data, which complicates use in scenarios where data isn’t available.
Introducing SeedLM
Researchers from Apple and Meta AI have developed SeedLM, a new way to compress LLM weights without needing any data for calibration. SeedLM uses pseudo-random generators to reduce memory access while keeping processing efficient. By utilizing Linear Feedback Shift Registers (LFSRs), it generates random matrices during use, allowing for fewer memory accesses even if it increases computation slightly.
Key Benefits of SeedLM
- Data-Free Compression: Unlike other methods, SeedLM doesn’t need calibration data, making it easier to use.
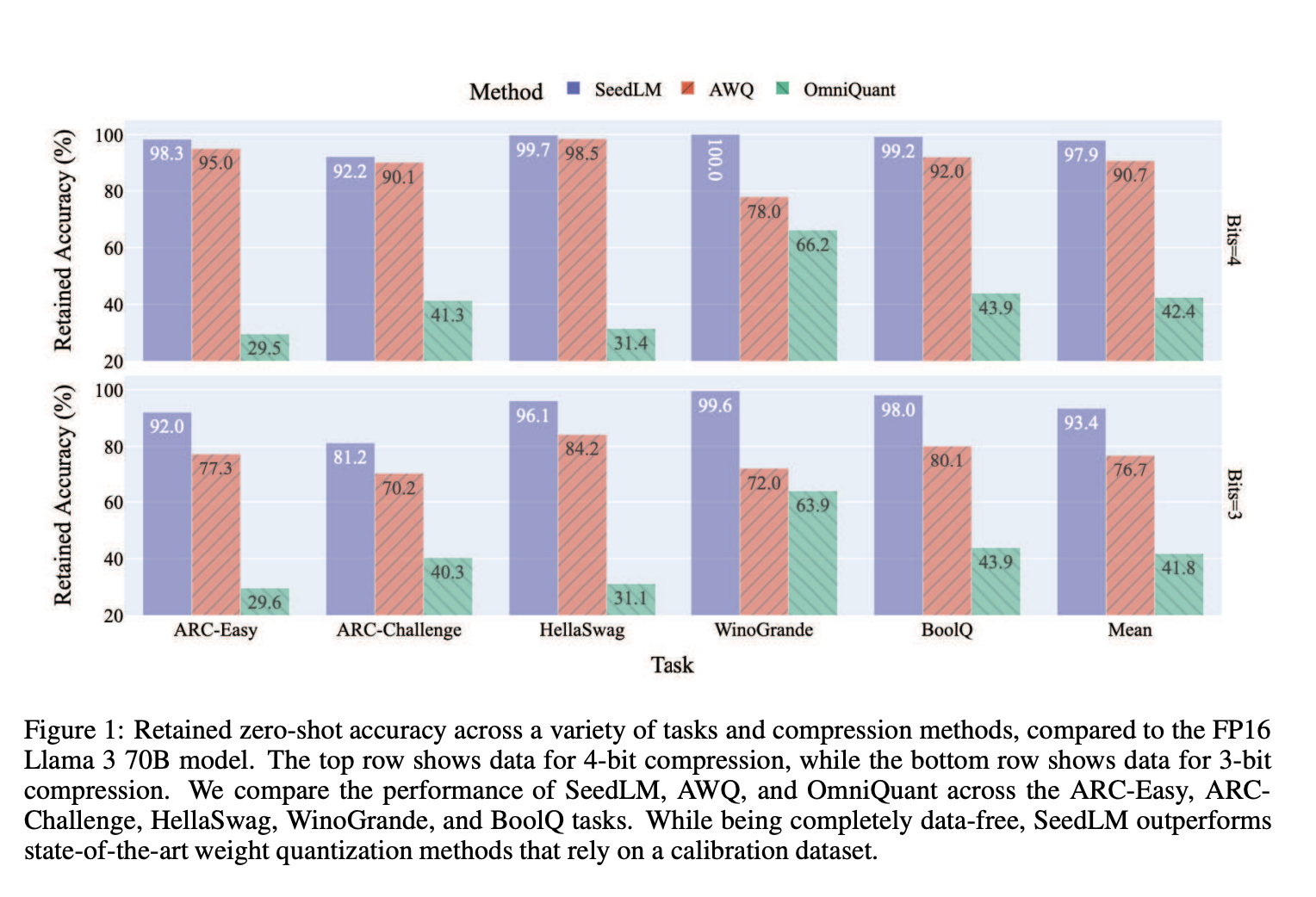
- High Accuracy: Maintains nearly the same accuracy as full models, achieving 97.9% accuracy at 4-bit precision.
- Efficient Weight Management: Compresses weights into 3-4 bits with minimal loss in quality.
- Energy Efficiency: Implemented in silicon, making it suitable for devices with limited resources.
How SeedLM Works
SeedLM compresses model weights by projecting them into pseudo-random bases generated by LFSRs. This method reduces the amount of memory needed by avoiding the storage of all individual weight values. Instead, it keeps only a seed and a few coefficients, allowing for quick reconstruction of weights during use.
Performance Results
SeedLM was tested on various models like Llama 2 and Llama 3, showing significant improvements over existing methods. In tests, it provided nearly a 4x speed-up for large models while preserving accuracy, especially in memory-bound tasks. The 4-bit version retained almost 99% of baseline performance, highlighting its effectiveness.
Conclusion
SeedLM offers a smart solution for compressing LLM weights, making it easier to deploy large models on devices with limited memory and energy resources. By simplifying the compression process and eliminating the need for calibration data, it enables high-performance applications across various environments.
Stay Updated
Check out the research paper for more details. Follow us on Twitter, join our Telegram Channel, and connect on LinkedIn. If you appreciate our work, subscribe to our newsletter and join our 50k+ ML SubReddit community.
Upcoming Webinar
Join us on October 29, 2024, for a live webinar on the best platform for serving fine-tuned models: the Predibase Inference Engine.
Leverage AI for Your Business
To enhance your company with AI and stay competitive, consider how SeedLM can transform your processes. Identify automation opportunities, define KPIs, select AI solutions tailored to your needs, and implement gradually. For assistance with AI KPI management, contact us at hello@itinai.com.
Learn more about how AI can improve your sales and customer engagement at itinai.com.






















