
Understanding Hierarchical Imitation Learning (HIL)
Hierarchical Imitation Learning (HIL) helps in making long-term decisions by breaking tasks into smaller goals. However, it struggles with limited supervision and requires a lot of expert examples. Large Language Models (LLMs), like GPT-4, improve this process by understanding language and reasoning better. By using LLMs, decision-making agents can learn sub-goals more effectively. Yet, current methods still face challenges with updating tasks dynamically and depend on lower-level agents for execution. This raises the question: Can pre-trained LLMs independently create task hierarchies and guide both sub-goal and agent learning?
Imitation Learning (IL) Overview
Imitation Learning (IL) includes Behavioral Cloning (BC) and Inverse Reinforcement Learning (IRL). BC learns from existing expert data but struggles with errors in new situations. IRL, on the other hand, requires interaction with the environment to understand the expert’s reward system, making it more resource-heavy. HIL improves IL by breaking tasks into sub-goals. LLMs assist in creating high-level plans, aiding in identifying sub-goals and learning actions, although they still rely on lower-level planners for execution.
Introducing SEAL: A New Framework
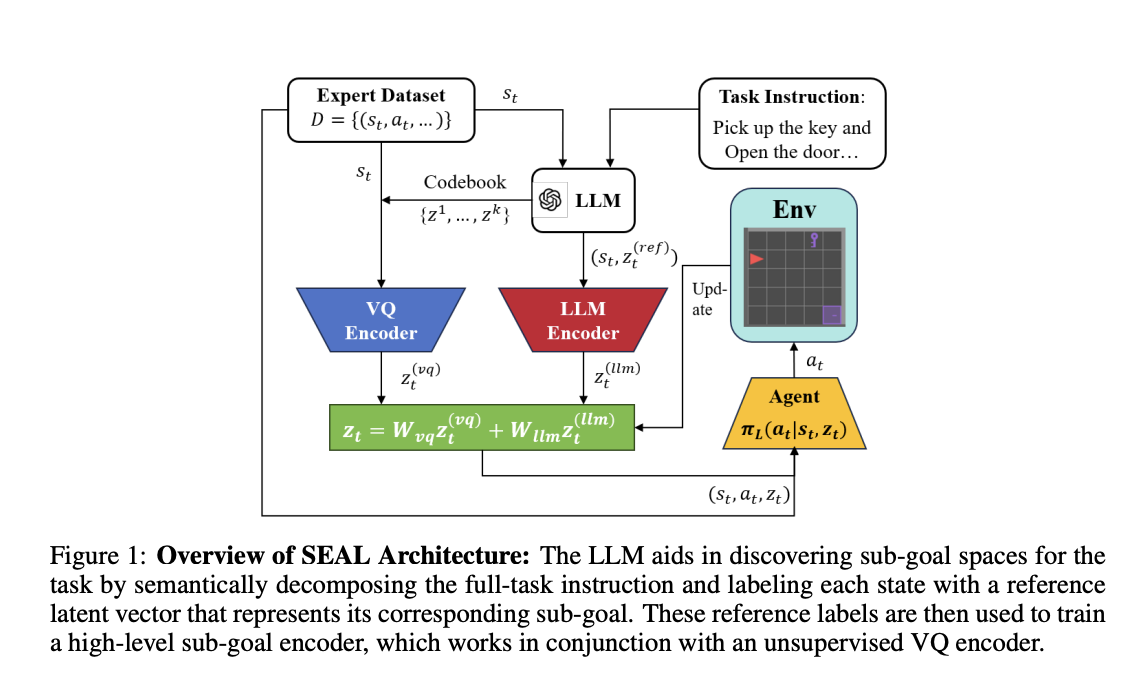
Researchers from the University of Alberta and a leading science and technology institution in Hong Kong have developed SEAL, a new HIL framework that uses LLMs to create meaningful sub-goals and pre-label states without needing prior knowledge of task hierarchies. SEAL features a dual-encoder system that combines LLM-guided supervised learning with unsupervised Vector Quantization (VQ) for strong sub-goal representation. It also includes a low-level planner to manage transitions between sub-goals effectively. Experiments show that SEAL outperforms existing HIL methods, especially in complex tasks with limited expert data.
Key Benefits of SEAL
- Cost-Effective: Generates sub-goal labels without expensive human input.
- High-Level Planning: Extracts sub-goal plans from task instructions.
- Robust Learning: Combines supervised and unsupervised learning for better sub-goal representation.
- Improved Training: Focuses on transitions between sub-goals for enhanced low-level policy training.
Performance Evaluation
The SEAL model was tested on two complex tasks: KeyDoor and Grid-World. KeyDoor is simpler, requiring players to get a key to unlock a door, while Grid-World involves collecting objects in a specific order. Results show that SEAL consistently outperforms most baseline models, thanks to its dual-encoder design that improves sub-goal achievement and transitions, even in challenging scenarios.
Conclusion
SEAL is an innovative HIL framework that leverages LLMs to create meaningful sub-goal representations without needing prior task hierarchy knowledge. It surpasses various baseline methods, especially in complex tasks with limited expert data. While SEAL shows great potential, it still faces challenges with training stability and aims to improve efficiency in partially observed states.
Get Involved
Check out the Paper. All credit for this research goes to the researchers involved. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. If you appreciate our work, subscribe to our newsletter and join our 50k+ ML SubReddit.
Upcoming Event
RetrieveX – The GenAI Data Retrieval Conference on Oct 17, 2023.
Transform Your Business with AI
Stay competitive and leverage SEAL to enhance your decision-making processes:
- Identify Automation Opportunities: Find key areas for AI integration.
- Define KPIs: Ensure measurable impacts from your AI initiatives.
- Select an AI Solution: Choose tools that fit your specific needs.
- Implement Gradually: Start small, gather data, and expand wisely.
For AI KPI management advice, contact us at hello@itinai.com. For ongoing insights, follow us on Telegram or Twitter.
Explore AI Solutions
Discover how AI can enhance your sales processes and customer engagement at itinai.com.


























