
Advancements in Language Models and Evaluation
Understanding the Progress
Large Language Models (LLMs) have improved significantly, especially in handling longer texts. This means they can provide more accurate and relevant responses by considering more information. With better context management, these models can learn from more examples and follow complex instructions effectively.
The Challenge of Evaluation
However, the tools we use to evaluate these models have not kept up. Current benchmarks like Longbench and L-Eval only assess up to 40,000 tokens, while modern LLMs can handle hundreds of thousands or even millions of tokens. This creates a gap between what models can do and how we measure their performance.
Emerging Evaluation Frameworks
The evolution of long-context evaluation benchmarks started with Long Range Arena (LRA), which managed up to 16,000 tokens but was limited to specific tasks. Newer frameworks like LongBench, Scrolls, and L-Eval now cover a wider range of tasks, from summarization to code completion, with token limits between 3,000 and 60,000. Recent benchmarks such as LongAlign and LongICLBench focus on in-context learning, while datasets like InfinityBench and NovelQA push boundaries further, handling up to 636,000 tokens.
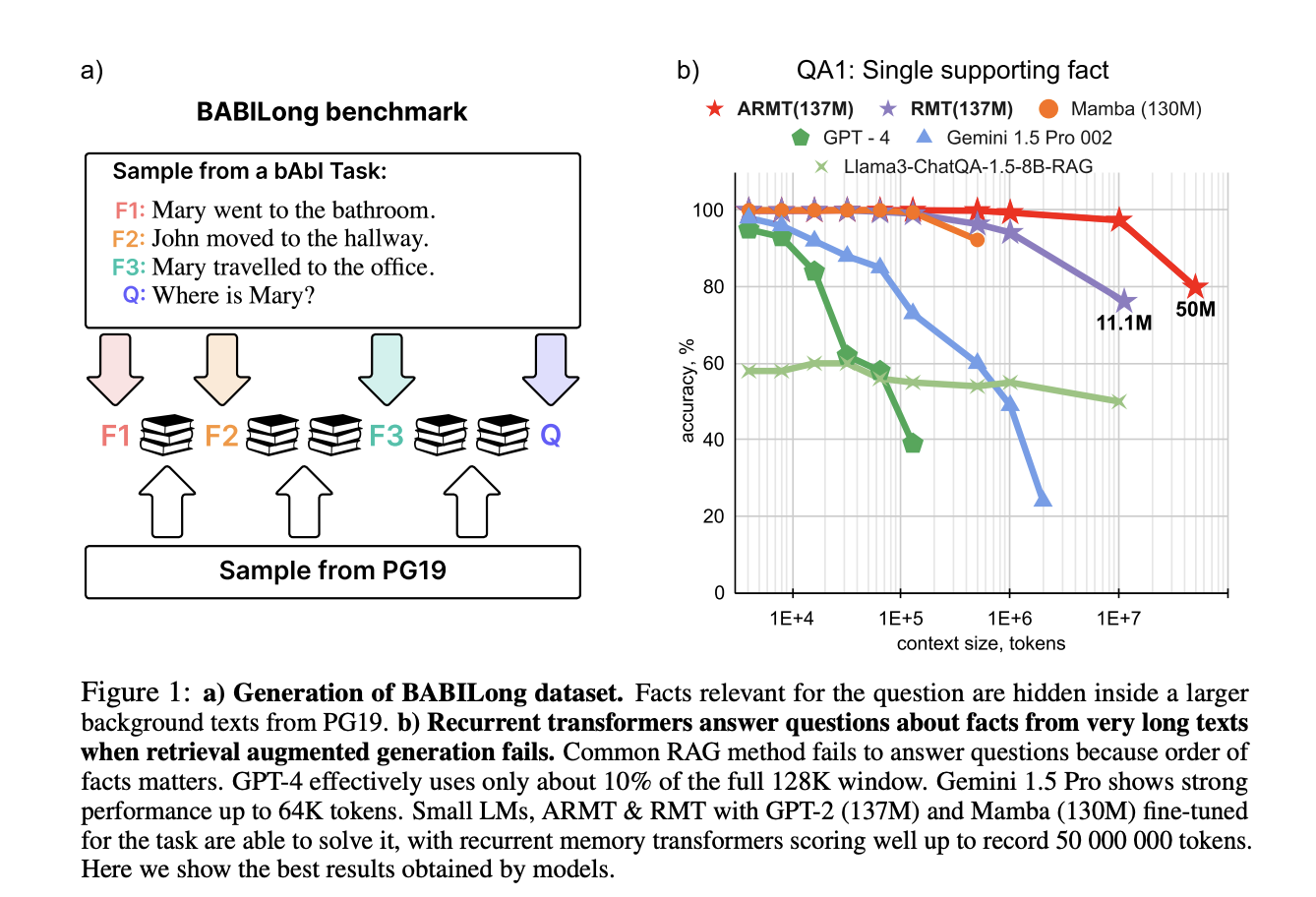
Introducing BABILong
Researchers have introduced BABILong, a benchmark designed to test language models’ reasoning abilities with very long documents. This framework includes 20 reasoning tasks, like fact chaining and deduction, using books from the PG19 dataset. It allows testing sequences of up to 50 million tokens, revealing that many current models only effectively use 10-20% of their available context.
Unique Evaluation Methodology
BABILong uses a unique approach to evaluate models by embedding relevant sentences within irrelevant text. This simulates real-world situations where important information is spread across long documents. The benchmark builds on original bAbI tasks, testing cognitive skills like spatial reasoning and deduction while avoiding training data contamination.
Context Utilization Insights
Analysis shows that many LLMs struggle with long sequences, utilizing only 10-20% of their context window. Among 34 tested models, only 23 met the benchmark accuracy. While models like GPT-4 perform well with up to 16,000 tokens, others falter beyond 4,000. Newer models like Qwen-2.5 show promise, and fine-tuned models like ARMT excel, processing sequences up to 50 million tokens.
Significant Advancements
BABILong marks a key step forward in evaluating long-context capabilities. Its design allows testing from 0 to 10 million tokens while controlling document length and fact placement. Despite improvements in newer models, they still face challenges. Fine-tuning has shown that even smaller models like RMT and ARMT can perform well on BABILong tasks, with ARMT achieving outstanding results.
Get Involved
Check out the Paper for detailed insights. Thanks to the researchers behind this project. Follow us on Twitter, join our Telegram Channel, and connect with our LinkedIn Group. Also, be part of our 60k+ ML SubReddit community.
Transform Your Business with AI
To stay competitive, leverage the insights from BABILong in your organization.
– **Identify Automation Opportunities**: Find key areas for AI integration.
– **Define KPIs**: Measure the impact of your AI initiatives.
– **Select the Right AI Solutions**: Choose customizable tools that fit your needs.
– **Implement Gradually**: Start small, gather data, and expand wisely.
For AI KPI management advice, reach out to us at hello@itinai.com. Stay updated with our insights on Telegram at t.me/itinainews or follow us on Twitter @itinaicom.
Discover how AI can enhance your sales and customer engagement at itinai.com.
























