
Enhancing Reward Models for AI Applications
Introduction to Reward Modeling
Reinforcement Learning (RL) has emerged as a crucial method for improving the capabilities of Large Language Models (LLMs). By focusing on human alignment, long-term reasoning, and adaptability, RL enhances the performance of these models. However, a significant challenge remains: generating accurate reward signals in diverse and less structured domains. Traditional reward models often rely on rule-based systems or specific tasks, which limits their applicability in broader contexts.
Challenges in Reward Modeling
Current reward models face difficulties in producing reliable and high-quality rewards across various tasks due to the subjective nature of reward criteria. To address this, researchers are exploring generalist reward models (RMs) that can adapt to a wider range of applications. However, these models must maintain a balance between flexibility and scalability during inference.
Existing Approaches
- Scalar Models: These models provide limited feedback and struggle with diversity.
- Semi-Scalar Models: They offer a middle ground but still face challenges in flexibility.
- Generative Reward Models (GRMs): These models produce richer outputs and are better suited for evaluating various responses.
Innovative Solutions: SPCT and Inference-Time Optimization
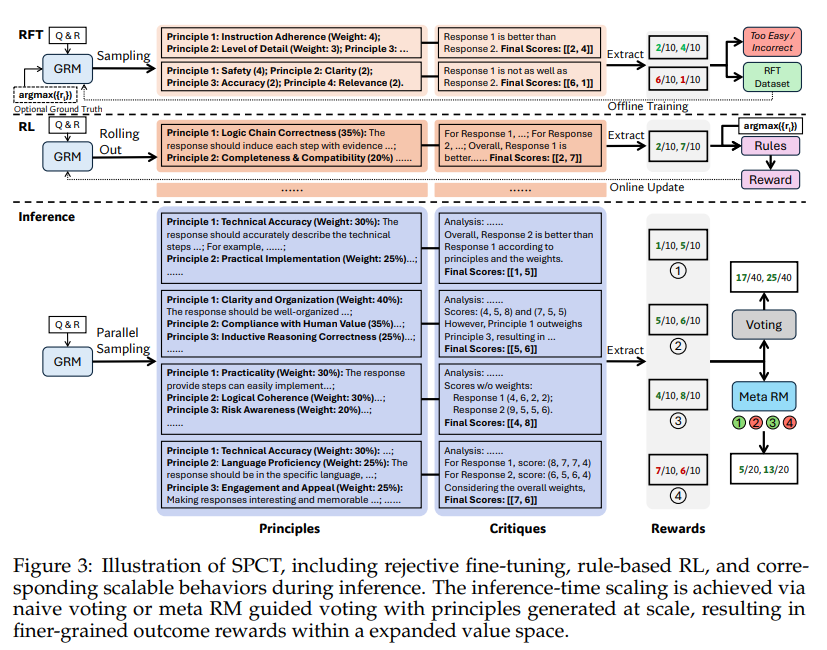
Researchers from DeepSeek-AI and Tsinghua University have developed methods to enhance the scalability of reward models. They introduced Self-Principled Critique Tuning (SPCT), which allows GRMs to generate adaptive principles and critiques during online reinforcement learning. This method includes:
- Rejective Fine-Tuning: Initializes principle and critique generation.
- Rule-Based Reinforcement Learning: Refines the generated principles dynamically during inference.
Performance Improvements
By employing parallel sampling and a meta reward model, the DeepSeek-GRM models have shown significant improvements in reward quality and scalability. These models consistently outperform existing benchmarks and rival top public models like GPT-4o. Key findings include:
- Inference-time scaling boosts performance significantly.
- Ablation studies emphasize the importance of principle generation and non-hinted sampling.
- Training-time scaling yields diminishing returns compared to inference-time strategies.
Case Study: DeepSeek-GRM
The DeepSeek-GRM-27B model exemplifies the effectiveness of these innovations. It has demonstrated superior performance across various benchmarks, achieving results comparable to larger models without the need for increased size. This highlights the potential for scalable and robust reward modeling in AI applications.
Conclusion
The introduction of SPCT marks a significant advancement in the scalability of generative reward models. By enabling adaptive principle and critique generation, SPCT enhances reward quality across diverse tasks. The DeepSeek-GRM models, particularly when paired with a meta reward model, demonstrate strong performance and scalability. Future initiatives will focus on integrating GRMs into RL pipelines and co-scaling with policy models, paving the way for more reliable and effective AI systems.
Call to Action
Explore how artificial intelligence can transform your business processes. Identify areas for automation, establish key performance indicators (KPIs), and select tools that align with your objectives. Start with small projects to gather data and gradually expand your AI initiatives. For expert guidance on managing AI in business, contact us at hello@itinai.ru or follow us on social media.



























