
Understanding VLM2VEC and MMEB: A New Era in Multimodal AI
Introduction to Multimodal Embeddings
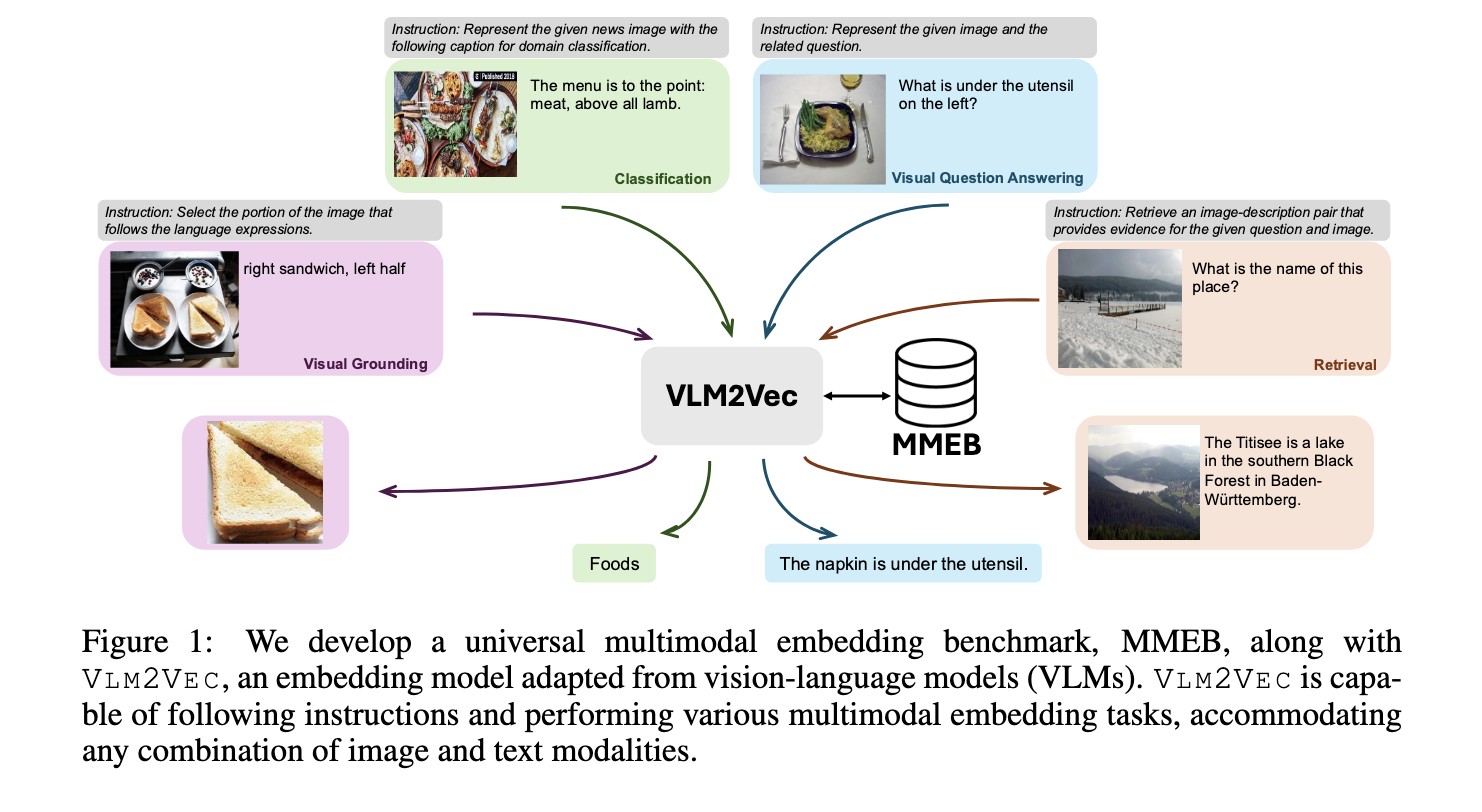
Multimodal embeddings integrate visual and textual data, allowing systems to interpret and relate images and language in a meaningful way. This technology is crucial for various applications, including:
- Visual Question Answering
- Information Retrieval
- Classification
- Visual Grounding
These capabilities are essential for AI models that analyze real-world content, such as digital assistants and visual search engines.
The Challenge of Generalization
A significant challenge in the field has been the difficulty of existing models to generalize across different tasks and modalities. Most models are designed for specific tasks and struggle with unfamiliar datasets. Additionally, the lack of a unified benchmark leads to inconsistent evaluations, limiting the models’ effectiveness in real-world applications.
Existing Solutions and Their Limitations
Current tools like CLIP, BLIP, and SigLIP generate visual-textual embeddings but face limitations in cross-modal reasoning. These models typically use separate encoders for images and text, merging their outputs through basic methods. As a result, they often underperform in zero-shot scenarios due to shallow integration and insufficient task-specific training.
Introducing VLM2VEC and MMEB
A collaboration between Salesforce Research and the University of Waterloo has led to the development of VLM2VEC, paired with a comprehensive benchmark known as MMEB. This benchmark includes:
- 36 datasets
- Four major tasks: classification, visual question answering, retrieval, and visual grounding
- 20 datasets for training and 16 for evaluation, including out-of-distribution tasks
The VLM2VEC framework utilizes contrastive training to convert any vision-language model into an effective embedding model, enabling it to process diverse combinations of text and images.
How VLM2VEC Works
The research team employed backbone models such as Phi-3.5-V and LLaVA-1.6. The process involves:
- Creating task-specific queries and targets.
- Using a vision-language model to generate embeddings.
- Applying contrastive training with the InfoNCE loss function to enhance alignment of embeddings.
- Utilizing GradCache for efficient memory management during training.
This structured approach allows VLM2VEC to adapt its encoding based on the task, significantly improving generalization.
Performance Outcomes
The results indicate a substantial improvement in performance. The best version of VLM2VEC achieved:
- Precision@1 score of 62.9% across all MMEB datasets.
- Strong zero-shot performance with a score of 57.1% on out-of-distribution datasets.
- Improvement of 18.2 points over the best baseline model without fine-tuning.
These findings highlight the effectiveness of VLM2VEC in comparison to traditional models, demonstrating its potential for scalable and adaptable multimodal AI applications.
Conclusion
The introduction of VLM2VEC and MMEB addresses the limitations of existing multimodal embedding tools by providing a robust framework for generalization across tasks. This advancement represents a significant leap forward in the development of multimodal AI, making it more versatile and efficient for real-world applications.

























